Chapter 10 Adding Sorted Sets Commands
Contents
What we’ll cover
With support for Sets added in the previous chapter, our server is now only two data types short of the real Redis. In this chapter we will focus exclusively on Sorted Sets.
Sorted sets are very similar to sets, with one major difference, instead of members being only strings, members are pairs of strings and floats, where the float value is used to sort members and is called the score. As mentioned in the previous chapters, Sets do not guarantee ordering and while the IntSet structure happened to provide a sorted data structure, the Dict class doesn’t guarantee any ordering and calling SMEMBERS would not always return elements in the same order. Every command that returns all the elements in a set would show this behavior, which is the case for SUNION, SDIFF and SINTER.
On the other hand, sorted sets guarantee ordering, but because the score value is not unique, members are sorted by the lexicographic of the member if scores are equal. Let’s look at a few examples:
127.0.0.1:6379> ZADD z 1.1 a 2.2 b 3.3 c 4 d 5.0 e 6e2 f 0 zero
(integer) 7
127.0.0.1:6379> ZRANGE z 0 -1
1) "zero"
2) "a"
3) "b"
4) "c"
5) "d"
6) "e"
7) "f"
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "zero"
2) "0"
3) "a"
4) "1.1000000000000001"
5) "b"
6) "2.2000000000000002"
7) "c"
8) "3.2999999999999998"
9) "d"
10) "4"
11) "e"
12) "5"
13) "f"
14) "600"
The first thing to note is that all sorted set commands are prefixed with a Z, and a sorted set if often referred to as a “zset” throughout the Redis codebase. As a matter of fact, all the sorted set commands are implemented in the t_zset.c file.
Members are added with ZADD, which accepts an even list of arguments after the key of the zset itself, z in the example, the first element of each member pair must be a valid float, as defined in the Chapter 7 when we added the HINCRBYFLOAT command or in Chapter 6 when we added validation for the timeout values for the blocking commands on lists. This means that besides “regular” values such as 5 or 26.2, scores can also be expressed with the E notation, 7.03e1 for 70.3, and the strings inf and infinity, with or without the + and - signs are accepted, in a case insensitive way.
ZRANGE 0 -1 returns all the members, without scores, similarly to the LRANGE command for lists. We can add the WITHSCORES option to include the scores. In both examples we can see that the order of elements in the RESP array returned by ZRANGE ordered the elements by their score values.
You might have noticed that we’ve already observed issues with the accuracy of the float values. a, b & c all show rounding errors with the WITHSCORES option, which we can also illustrate with the ZSCORE command that returns the score of the given member:
127.0.0.1:6379> ZSCORE z a
"1.1000000000000001"
127.0.0.1:6379> ZSCORE z b
"2.2000000000000002"
127.0.0.1:6379> ZSCORE z c
"3.2999999999999998"
These issues are the exact same we discussed in Chapter 7 when implementing the HINCRBYFLOAT command. That being said, we can see that the precision of the score value in a zset seems to be worse than what HINCRBYFLOAT provided:
127.0.0.1:6379> HINCRBYFLOAT h a 1.1
"1.1"
127.0.0.1:6379> HGETALL h
1) "a"
2) "1.1"
This difference in precision is because Redis uses a double for the score field in a zset, whereas it uses a long double when performing the operation in HINCRBYFLOAT.
One reason that might justify this choice is that values are stored as strings in a hash, so the extra bytes required to allocate a long double are only temporary, while performing the operation. On the other hand, the score is always stored as a number, alongside the member value as a string, in a zset, so the extra bytes required for a long double would affect the memory usage of the server significantly for large zsets.
Let’s approximate this difference. A double uses eight bytes, and a long double uses sixteen. Setting aside some of the overhead required by the data structure actually storing the sorted sets, we can infer that the size of a sorted set elements would be at least 'number of bytes in member' + 8 with a double and 'number of bytes in member' + 16 with a long double. While the difference might seem small, it means that a sorted set with 1,000,000,000 members would use an extra 8,000,000,000 bytes with a long double, 16,000,000,000 bytes compared to 8,000,000,000 bytes to store the scores, that’s about 8 gigabytes (GB), or about 7.45 gibibytes (GiB) of memory!
The two units are similar but different by a small factor, a kilobyte (KB) is 1,000 bytes, and a kibibyte (KiB) is 1,024 bytes, 2^10, a megabyte (MB) is 1,000,000 bytes, and a mebibyte (MiB) is 1,048,576 bytes, 2^20, or 1,204 * 1,024, and so on, you multiply by 1,000 in one case, and by 1,024 in the other. ISO-80000, or IEC 80000 is the standard the introduced these Binary Prefix units.
And we’ll see in the next section that Redis actually stores the score twice, so this difference would actually be at least two bytes per member.
It’s also important to consider the trade-offs and the actual impact of these precision issues. It seems fair to expect a high level of precision for the increment commands, INCRBYFLOAT and HINCRBYFLOAT, as users are given the ability to perform operations on the values and use the results in their application. On the other hand, the score value is only used for ordering, meaning that these precision issues aren’t that impactful, as long as they’re consistent. In the previous example, despite the precision issues, we still observe the expected behavior, 1.1000000000000001 is lower than 2.2000000000000002 and the order of members is the same as if the scores had been precisely 1.1 and 2.2.
The consistency aspect is also important, because members are sorted by lexicographic order if members are equal, let’s look at an example by adding another member with an identical score:
127.0.0.1:6379> ZADD z 1.1 a
(integer) 0
127.0.0.1:6379> ZADD z 1.1 aa
(integer) 1
127.0.0.1:6379> ZADD z 1.1 ab
(integer) 1
The first ZADD call returned 0, because the sorted set already contains the member a. The next two calls both returned 1 because aa and ab were both successfully added, with the same score as a, so let’s look at the order of members now:
127.0.0.1:6379> ZRANGE z 0 -1
1) "zero"
2) "a"
3) "aa"
4) "ab"
5) "b"
6) "c"
7) "d"
8) "e"
9) "f"
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "zero"
2) "0"
3) "a"
4) "1.1000000000000001"
5) "aa"
6) "1.1000000000000001"
7) "ab"
8) "1.1000000000000001"
9) "b"
10) "2.2000000000000002"
11) "c"
12) "3.2999999999999998"
13) "d"
14) "4"
15) "e"
16) "5"
17) "f"
18) "600"
We can see that aa and ab were both added after a and before b. The three elements with identical scores are ordered by lexicographical order: a < aa < ab.
While we could mimic the Redis behavior and use the Ruby Float class for the score value in a zset, and keep using BigDecimal for the increment operations, we will keep using BigDecimal to keep things simpler. As mentioned previously, the Server we’re building does not try to optimize every single aspects, which we would be a losing battle by using such a high level language as Ruby.
Redis supports twenty eight (!!) commands for Sorted Sets, and we’ll implement all of them except ZSCAN for the same reasons outlined in Chapter 8. Because all the *SCAN commands are complicated and deserve their own chapter.
- ZADD: Add one or more members (with their scores) to a sorted set, creating it if necessary
- ZCARD: Return the cardinality of the set, the number of members
- ZRANGE: Return all the members with an index within the given range
- ZRANGEBYLEX: Return all the members with a member value within the given lexicographic range
- ZRANGEBYSCORE: Return all the members with a score value within the given score range
- ZSCORE: Return the score of a member
- ZMSCORE: Return the scores for all the given members
- ZRANK: Return the rank, its 0-based index in the set, of a member
- ZREM: Remove a member from the set
- ZREMRANGEBYLEX: Remove all the members within the lexicographic range
- ZREMRANGEBYRANK: Remove all the members within the rank range
- ZREMRANGEBYSCORE: Remove all the members within the score range
- ZREVRANGE: Return all the members with an index within the given range, sorted by descending score
- ZREVRANGEBYLEX: Return all the members with an index within the given lexicographic range, sorted by descending lexicographic order
- ZREVRANGEBYSCORE: Return all the members with an index within the given score range, sorted by descending score
- ZREVRANK: Return the rank of a member, as if it was sorted by descending score
- ZINTER: Return the intersection of multiple sets
- ZINTERSTORE: Store the intersection of multiple sets in another key
- ZUNION: Return the union of multiple sets
- ZUNIONSTORE: Store the union of multiple sets in another key
- ZPOPMAX: Remove the member with the highest score
- ZPOPMIN: Remove the member with the smallest score
- BZPOPMAX: Blocking variant of
ZPOPMAX - BZPOPMIN: Blocking variant of
ZPOPMIN - ZCOUNT: Count the number of members with a score in the given range
- ZLEXCOUNT: Count the number of members within the given lexicographic range
- ZINCRBY: Increment the score of a member
Twenty-seven commands await us, it’s gonna be a long chapter, and we have a lot of code to go through, buckle up!
How Redis does it
As we’ve seen in the last two chapters, Redis uses two underlying structures, depending on the size of the sorted sets to implement the sorted set API. The two criteria are similar to the ones used for the hash structure, the number of entries, configured through zset-max-ziplist-entries, with a default value of 128 and the length of the members themselves, configured with zset-max-ziplist-value, with a default value of 64.
As long as the size of the sorted set is below zset-max-ziplist-entries and as long as each member’s length is below zset-max-ziplist-value, the sorted set elements will be stored in a ziplist. The choice of a ziplist as a data structure for small sorted sets is driven by the same reasons Redis uses a ziplist for small hashes.
Let’s quickly confirm this with redis-cli, DEBUG OBJECT, irb and the redis gem:
127.0.0.1:6379> ZADD z 0 1
(integer) 1
127.0.0.1:6379> DEBUG OBJECT z
Value at:0x7fef01405b70 refcount:1 encoding:ziplist serializedlength:16 lru:11787108 lru_seconds_idle:3
Now let’s add 127 members to the sorted set:
irb(main):001:0> require 'redis'
=> true
irb(main):002:0> red = Redis.new; 127.times { |i| red.zadd('z', i, i) }
=> 127
And let’s inspect things back in redis-cli:
127.0.0.1:6379> ZCARD z
(integer) 128
127.0.0.1:6379> DEBUG OBJECT z
Value at:0x7fa078f05810 refcount:1 encoding:ziplist serializedlength:533 lru:11787457 lru_seconds_idle:2
127.0.0.1:6379> ZADD z 0 b
(integer) 1
127.0.0.1:6379> DEBUG OBJECT z
Value at:0x7fa078f05810 refcount:1 encoding:skiplist serializedlength:1292 lru:11787463 lru_seconds_idle:2
127.0.0.1:6379> ZCARD z
(integer) 129
With 128 items the set is still using a ziplist, and as long as we get past that, it becomes a skiplist.
If any of the two constraints is not met, Redis switches to a combination of a dict and a skiplist. The dict stores members as keys, which is similar to what we did in the previous chapter for sets, and the value is the score. While this is enough to guarantee uniqueness, as well as store the score values, it is problematic if we were to call the ZRANGE command to return the first element, with ZRANGE z 0 0. In order to know which member is the first one, we’d need to iterate through the whole dict, to find the member with the smallest score.
In order to make these operations faster, Redis also stores the member and score values in a skiplist. A skiplist is a data structure that maintains its element sorted and provides some of the benefits of a linked list, such as efficient adding and removal operations, while also providing an efficient way to search for elements, with an O(logn) time complexity. Using a “regular” linked list would have an O(n) time complexity for search.
Redis stores both the string and the score in the skiplist, allowing it to efficiently retrieve sorted set members based on their position according to the ordering by score. This position is called “rank”.
Implementing a skiplist is fairly complicated, and Redis uses a modified version which stores extra information, so given how much work we already have ahead of us, we will not implement it in this chapter. We will instead use a similar approach by modifying our SortedArray class. It’s important to note that by using a sorted array, our sorted set implementation will suffer from the same problems we described about the ziplist becoming expensive to manipulate as they grow. This drawback is a conscious decision made in order to focus on other parts of the sorted set implementations, while keeping some of the original ideas, that is the two data structures approach.
The following is an illustration of what a skiplist looks like, the arrows can be seen as “express lanes”. The skiplist paper goes into more details if you’re interested in learning more about this structure:
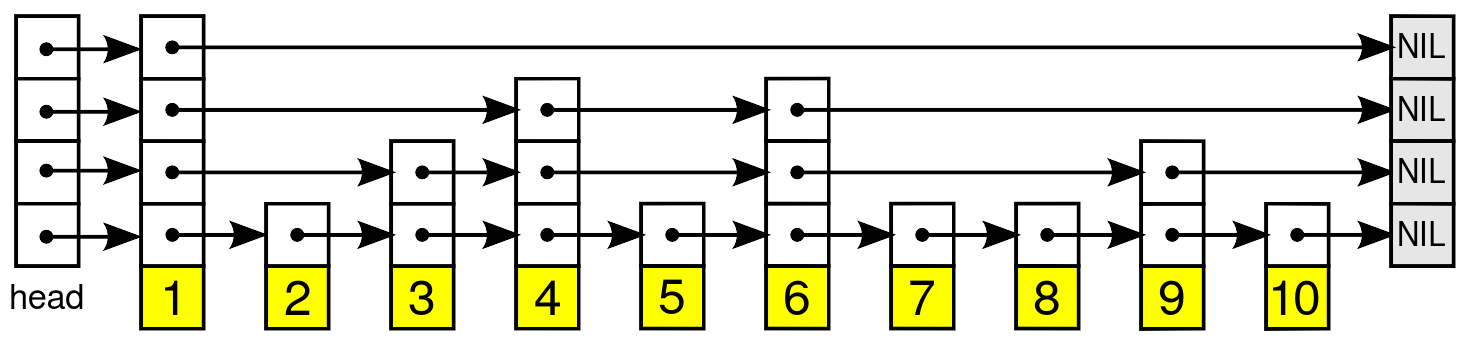
The tl;dr; is that the arrows seen above, the “express lanes”, can be used to ignore big chunks of the list when searching for an element. The search process always starts from the top left, and follows arrows as needed. Say that we’d be searching for the number 7, we’d follow the first arrow, see that nothing is on the other end, so move to the second arrow, it would point us to 4, which given that we know that the list is sorted, gives us a chance to find 7 if we were to keep looping, following the arrow would take us to 6, following it again would take us to the end of the list, so we would move to the one below and find 9, which means that 7 cannot be found if we were to continue over there, so we keep going down, and land on 7. The image below highlights all the steps that we would take to find 7, where the red arrows show the paths we chose not to follow and the green ones the ones we did.
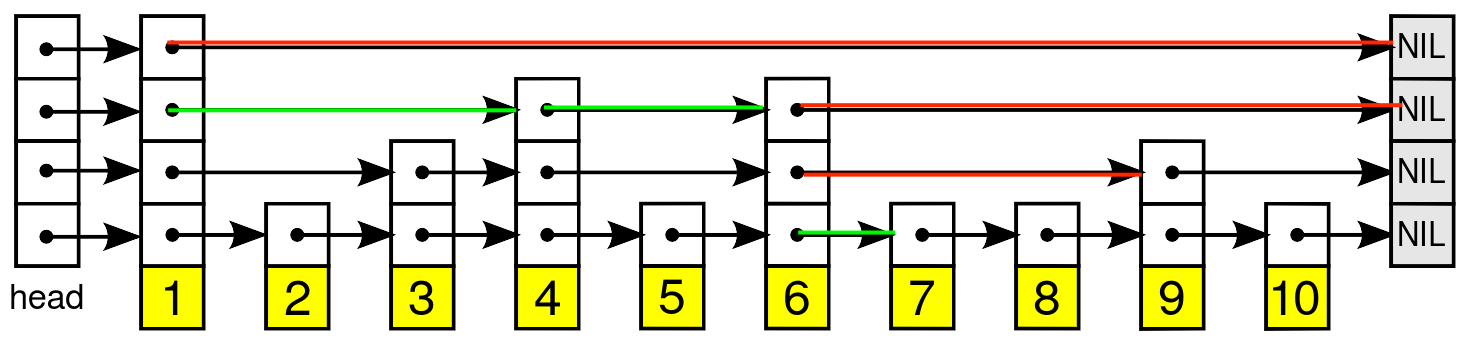
The next example shows the path we would take if we were to search for 11:
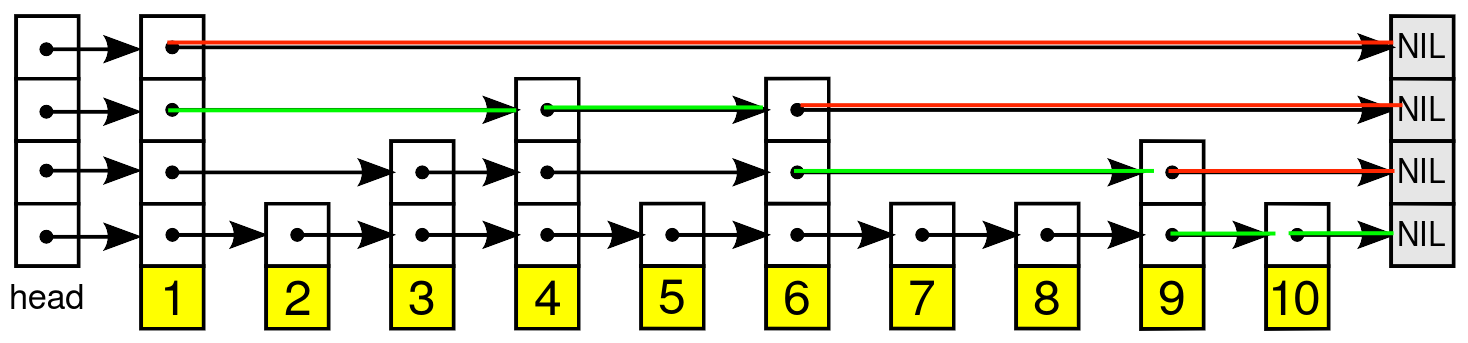
Note that Redis optimizes a few things such as storing a reference to the tail of the list, which would have sped up the process to find 11.
Updating our SortedArray class
As we mentioned earlier we will not implement a skiplist in this chapter, we will instead reuse our SortedArray class to store member/score pairs, ordered by their score, and by member if scores are equal.
The initial version of SortedArray used to accept a field argument for its constructor, and it would use this field to order elements within the array. We used this with SortedArray.new(:timeout) to order BlockedState instances, which have a timeout field.
The field was used to compare elements in blocks passed to Array#bsearch_index calls.
The main change we want is for SortedArray instances to consider multiple fields, from left to right. The use case is that we want our SortedArray to store objects with a score field, and a member field, if the scores are different, we want elements to be ordered by score, otherwise, by member. In other words, the primary ordering is through scores and the member acts as a tiebreaker.
It’s worth noting that this approach, similarly to the skiplist in Redis, does not enforce member uniqueness, this is the responsibility of the caller to check for member uniqueness and is what we will use a Dict for.
There are different ways to solve the problem we’re facing now, we could even create a new class, ScoreAndMemberSortedArray, and rename the current one to TimeoutSortedArray. Instead we will refactor the class to work with any number of fields. In order to do so, we will replace the argument from field, to &block, and let callers pass the block that will be fed to bsearch_index:
require 'forwardable'
module BYORedis
class SortedArray
extend Forwardable
def_delegators :@underlying, :[], :delete_if, :size, :each, :delete_at, :shift,
:bsearch_index, :map, :each_with_index, :pop, :empty?
def initialize(&block)
@underlying = []
@block = block
end
def push(new_element)
if @underlying.empty?
index = 0
else
index = @underlying.bsearch_index do |element|
@block.call(element, new_element) <= 0
end
end
index = @underlying.size if index.nil?
@underlying.insert(index, new_element)
end
alias << push
end
end
listing 10.1 The updated push method in the SortedArray class
Note that we added the Forwardable module to delegate a bunch of methods directly to the underlying array. The only difference between the new push method and the old one is the else branch, it used to be:
index = @underlying.bsearch_index do |element|
element.send(@field) >= new_element.send(@field)
end
The new version expects the block to return a “comparison value”, which is what we explored in the previous chapter with the “spaceship operator”. A negative value indicates that the left element is lower than the right one, 0 means that both elements are equal and a positive value means that left element is greater. While technically any negative or positive values are valid, the spaceship operator always returns -1, 0 or 1.
In the previous implementation, the block passed to bsearch_index was using the find-minimum mode, and was returning a boolean. The boolean would only be true if the field of the new element, timeout in practice, was lower than or equal to the one we’re comparing it with in the array.
As long as the @block given to the constructor is correctly created, it will return the same value, the following is the block that should be given for the behavior to stay the same:
SortedArray.new do |array_element, new_element|
new_element.timeout <=> array_element.timeout
end
The block will return -1 if:
new_element.timeout < array_element.timeout
it will return 0 if:
new_element.timeout == array_element.timeout
and will return 1 if
new_element.timeout > array_element.timeout
The value returned by the block will be <= 0 if and only if new_element.timeout <= array_element.timeout, so the behavior is the same!
With this change, we can now create a SortedArray that compares multiple fields!
SortedArray.new do |array_element, new_element|
score_comparison = new_element.score <=> array_element.score
if score_comparison == 0
new_element.member <=> array_element.member
else
score_comparison
end
end
If score_comparison is not 0, then the scores are different, and by returning score_comparison, our push methods will end up ordering elements by score values. The difference is if the score values are equal, if score_comparison == 0, in this case we use the member values as tiebreaker, and return the result of the spaceship operators between the members values.
Let’s now update the delete method:
module BYORedis
class SortedArray
# ...
def delete(element)
index = index(element)
return if index.nil?
element_at_index = @underlying[index]
first_index_to_delete = nil
number_of_items_to_delete = 0
while element_at_index
if element_at_index == element
first_index_to_delete ||= index
number_of_items_to_delete += 1
end
index += 1
next_element = @underlying[index]
if next_element && @block.call(next_element, element_at_index) == 0
element_at_index = next_element
else
break
end
end
@underlying.slice!(first_index_to_delete, number_of_items_to_delete)
end
def index(element)
if @underlying.empty?
nil
else
@underlying.bsearch_index do |existing_element|
@block.call(existing_element, element)
end
end
end
end
end
listing 10.2 The updated delete method in the SortedArray class
There are two differences between the new delete method and the previous one. First, we extracted an index method to return the index of a member, or nil if the element is not present.
The index method uses the @block variable with bsearch_index, but this time it passes the result of the block directly, which uses the find-any mode, in which it will return the index of the element, if it exists, and nil otherwise. Note that if there are duplicates, the left-most element is returned in this mode.
The rest of the delete method is almost identical, we grab the element at index index, and as long as they are equal according to @block, which we check with @block.call(next_element, element_at_index) == 0, we keep going right.
This last step was necessary for the timeout based use case. In the timeout array we might end up with multiple values sharing the same timeout, in which case, we want to find element within these.
Final touches
Creating a new instance of SortedArray is now a bit tedious, you need to know how to craft the block argument for it to work as expected, here is what it would look like to replace the timeout based sorted array:
SortedArray.new do |array_el, new_el|
new_el.timeout <=> array_el.timeout
end
It is even more complicated with our new use case, where we want to order items in the array by score, and fallback to member if the scores are equal:
SortedArray.new do |array_el, new_el|
score_comparison = new_el.score <=> array_el.score
if score_comparison == 0
new_el.member <=> array_el.member
else
score_comparison
end
end
Let’s improve this by providing a class method on SortedArray that creates the correct block based on the given fields:
module BYORedis
class SortedArray
# ...
def self.by_fields(*fields)
SortedArray.new do |array_element, new_element|
comparison = nil
fields.each do |field|
comparison = new_element.send(field) <=> array_element.send(field)
# As long as the members are equal for field, we keep comparing
if comparison == 0
next
else
break
end
end
comparison
end
end
end
end
listing 10.3 The by_fields class method for SortedArray
We can now easily create a sorted array for BlockedState with:
SortedArray.by_fields(:timeout)
And one for sorted set members with score and member attributes:
SortedArray.by_fields(:score, :member)
Perfect!
Creating and Updating Sorted Sets
With regular sets there is no concept of “update”, an element is a member of a set, or it isn’t, we can either add it or remove it. Things are different with sorted sets, now that members have a score value associated with them, we can update the score of an existing member in a sorted set. All these operations are performed with the ZADD command. We only saw some of the ways in which it can be used in the introduction to this chapter. It’s now time to add it to our server.
The ZADD command
In its simplest form, the ZADD command uses the format: zset-key score, member ... where score needs to be a valid float and must be followed by a string value as the member. We’ve already looked at some examples earlier in the chapter, so let’s now look at all the possible options:
NX|XX: WithNX, members can only be added and are never updated andXXnever adds new members, it only updates existing ones. The two options are mutually exclusive.LT|GT: These two options have been added in 6.2.0 and have not yet been implemented in this book. Only updates the members if the new score is respectively lower than or greater than the existing scoreCH: Return the number of changed, where “changed” means members added, or members updated. By default only the number of added member is returnedINCR: Limit the number of score/member pair to one, and increment the score for the given member by the new score, defaulting to0if the member was not present in the set. TheINCRoption changes the return value to the new score and ignores theCHoption.
The format is described as the following by the Redis Documentation:
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]
Let’s look at some examples now:
127.0.0.1:6379> ZADD z NX CH INCR 10.1 a
"10.1"
127.0.0.1:6379> ZADD z NX CH 5 a 2.2 b
(integer) 1
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "b"
2) "2.2000000000000002"
3) "a"
4) "10.1"
127.0.0.1:6379> ZADD z CH 5 a 2.2 b
(integer) 1
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "b"
2) "2.2000000000000002"
3) "a"
4) "5"
127.0.0.1:6379> ZADD z CH 5 a
(integer) 0
127.0.0.1:6379> ZADD z CH 6 a
(integer) 1
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "b"
2) "2.2000000000000002"
3) "a"
4) "6"
The first command, with the INCR option shows how it uses a default score value of 0 and added 10.1 to it. The CH option was overridden by the INCR option and the NX option did not do anything since the member was not already present.
In the second example, NX blocked a from being updated and only b was added, which counts as an update and is counted with the CH option.
The same command without the NX option updates both a and b, but because b has the same score, it is not updated and the count only includes the updated score of a.
The next command shows a changed count of 0 because the score is the same. Finally, changing the score to a different value, 6, returns a changed count of 1.
Let’s start by creating the sorted_set_commands.rb file with the ZAddCommand class.
require_relative './redis_sorted_set'
module BYORedis
class ZAddCommand < BaseCommand
def call
@options = {
presence: nil,
ch: false,
incr: false,
}
Utils.assert_args_length_greater_than(1, @args)
key = @args.shift
parse_options
raise RESPSyntaxError unless @args.length.even?
if @options[:incr] && @args.length > 2
raise ValidationError, 'ERR INCR option supports a single increment-element pair'
end
pairs = @args.each_slice(2).map do |pair|
score = Utils.validate_float(pair[0], 'ERR value is not a valid float')
member = pair[1]
[ score, member ]
end
sorted_set = @db.lookup_sorted_set_for_write(key)
return_count = 0
pairs.each do |pair|
sorted_set_add_result = sorted_set.add(pair[0], pair[1], options: @options)
if @options[:incr]
if sorted_set_add_result
return_count = Utils.float_to_string(sorted_set_add_result)
else
return_count = nil
end
elsif sorted_set_add_result
return_count += 1
end
end
RESPSerializer.serialize(return_count)
rescue FloatNaN
RESPError.new('ERR resulting score is not a number (NaN)')
end
def self.describe
Describe.new('zadd', -4, [ 'write', 'denyoom', 'fast' ], 1, 1, 1,
[ '@write', '@sortedset', '@fast' ])
end
private
def parse_options
@options = {}
loop do
# We peek at the first arg to see if it is an option
arg = @args[0]
case arg.downcase
when 'nx', 'xx' then set_presence_option(arg.downcase.to_sym)
when 'ch' then @options[:ch] = true
when 'incr' then @options[:incr] = true
else
# We found none of the known options, so let's stop here
break
end
# Since we didn't break, we consume the head of @args
@args.shift
end
end
def set_presence_option(option_value)
if @options[:presence] && @options[:presence] != option_value
raise ValidationError, 'ERR XX and NX options at the same time are not compatible'
else
@options[:presence] = option_value
end
end
end
end
listing 10.4 The ZAddCommand class in sorted_set_commands.rb
Handling all the various options makes the method longer than most other commands, let’s slowly step through it. We initially create a hash of default values for the three options, presence, which has three possible values, nil, the default, nx, or px. ch defaults to false and will be set to true only we find the ch option among the arguments. Finally, incr defaults to false and will be switched to true if we find incr among the arguments.
The validation of the length of the @args array is not as simple as it usually is, so we start by checking that we have at least one argument, and we’ll perform more validations later on. The first argument is the key of the sorted set, so we extract it with Array#shift and delegate the options handling to the private method parse_options
The tricky thing about parse_options is that it operates on an array of arguments, but it doesn’t know if it contains any options, since they’re all optional, so if @args was set to [ '1', 'a', '2', 'b' ], it shouldn’t do anything, but if the first elements of the array are valid options, it needs to extract and process them.
We use a “peek” approach, we look at the head of @args, with @args[0], and compare it with all the valid option values. We use String#downcase to make sure that we handle any case variants of the options, such as InCr or nx. If we find either nx or xx, we call set_presence_options. This method takes care of returning an error if the arguments contained both nx and xx, which is invalid, as well as setting the value in @options[:presence].
Back to parse_options, the other two cases are ch and incr, in either situation we set the corresponding value to true in the @options hash. If the head of @args does not match any of these cases, we abort the loop and exit the method, we’re done parsing options and we need to treat all the remaining elements as score/member pairs. If we did not exit the loop early with break, we reach the last line @args.shift, which effectively “consumes” the head of @args so that the next iteration sees the next element when it peeks at the head again.
Back to call, all valid options have been shifted from @args, and an exception was raise if any of the options were invalid, so if we’re back in call we know we have to handle all the elements in @args as member/score pairs. We start by checking that we have an even number of elements in the arguments array, to make sure that we’re indeed dealing with pairs. Redis fails early in this case. It could technically process the elements one by one and abort when it fails to find a pair of element, but it instead validates the arguments eagerly.
Next up, we need to confirm that we only received a single score/member pair if @options[:incr] was set to true through the INCR option.
If all these checks pass, we iterate over all the elements, two at a time with each_slice(2) and validates that first element of each pair is a valid float string. The array returned by Array#map will be an array of pairs, where the first element of the pair is the score, as a BigDecimal and the second element is the member, as a String.
Now that all the validations are behind us, we load the sorted set with DB#lookup_sorted_set_for_write, which we need to write:
module BYORedis
class DB
# ...
def lookup_sorted_set(key)
sorted_set = @data_store[key]
raise WrongTypeError if sorted_set && !sorted_set.is_a?(RedisSortedSet)
sorted_set
end
def lookup_sorted_set_for_write(key)
sorted_set = lookup_sorted_set(key)
if sorted_set.nil?
sorted_set = RedisSortedSet.new
@data_store[key] = sorted_set
if @blocking_keys[key]
@ready_keys[key] = nil
end
end
sorted_set
end
end
end
listing 10.5 The DB#lookup_sorted_set_for_write method
The @ready_keys[key] = nil line, under the if @blocking_keys[key] condition is similar to what we had to write in lookup_list_for_write when adding the BLPOP and BRPOP commands. We’re dealing with a similar situation here, blocking commands such as BZPOPMIN and BZPOPMAX, which will be implemented later in this chapter, can cause clients to be blocked until a sorted set can be popped from. The same way that Redis never stores empty list, it also never stores empty sorted sets, and the same applies to hashes and sets, which means that whenever we create a new sorted set, we might be able to unblock a client blocked for that key, adding it to ready_keys will allow us to check for that. We’ll explore this in more details when adding the two blocking commands for sorted sets.
Once the sorted_set variable is created, we initialize the return_count variable, its content will depend on the value of @options[:ch] or @options[:incr].
We then iterate over the pairs array, and for each pair we call RedisSortedSet#add with the score, the member and the @options hash.
If @options[:incr] was set to true we store the value returned by RedisSortedSet#add, as a BigDecimal in return_count and return it with RESPSerializer, which will either return the new cardinality as RESP integer or the new score, as string, since RESP2 does not have a dedicated float type.
We now need to dive into the RedisSortedSet#add method, which is the one that actually adds items to the sorted set:
require 'bigdecimal'
require_relative './dict'
require_relative './list'
require_relative './zset'
module BYORedis
class RedisSortedSet
Pair = Struct.new(:score, :member)
attr_reader :underlying
def initialize
@underlying = List.new
end
def add(score, member, options)
convert_to_zset if @underlying.is_a?(List) &&
member.length > Config.get_config(:zset_max_ziplist_value)
case @underlying
when List
added = add_list(score, member, options)
convert_to_zset if added && @cardinality >= Config.get_config(:zset_max_ziplist_entries)
added
when ZSet then @underlying.add(score, member, options)
else raise "Unknown type for #{ @underlying }"
end
end
private
def convert_to_zset
raise "#{ @underlying } is not a List" unless @underlying.is_a?(List)
zset = ZSet.new
@underlying.each do |pair|
zset.dict[pair.member] = pair.score
zset.array << pair
end
@underlying = zset
end
end
end
listing 10.6 The RedisSortedSet#add method
We declare a new Struct at the beginning of the class, Pair, which will hold the score/member pairs inside the List or within the ZSet. The ZSet class is the class that will coordinate the Dict and SortedArray instances, as described earlier in the chapter:
module BYORedis
class ZSet
attr_reader :dict, :array
def initialize
@dict = Dict.new
@array = SortedArray.by_fields(:score, :member)
end
end
end
listing 10.7 The ZSet class
Back to RedisSortedSet#add, we use the tried and true pattern of a case/when against @underlying to determine which data structure we’re currently dealing with. In the List case we delegate the logic to the add_list private method, and in the ZSet case we use the ZSet#add method.
Before looking at the process of adding or updating the score and member values in the List or the ZSet, let’s take a look at the convert_to_zset method. We need to iterate through all the elements in the list to add them to the newly created ZSet, so instead of using the List.left_to_right_iterator, which is pretty verbose, let’s add the List#each method:
module BYORedis
class List
# ...
def each(&block)
raise 'No block given' unless block
iterator = List.left_to_right_iterator(self)
while iterator.cursor
block.call(iterator.cursor.value)
iterator.next
end
end
# ...
end
end
listing 10.8 The List#each method
We won’t always be able to use the each method, there are cases where we’ll need to have a hold of the ListNode instance, to check the value of its prev_node for instance, and in these cases we’ll still need to use List.left_to_right_iterator. We’re about to see an example in the add_list method below.
Once all the members from the List instances have been added to the ZSet one, we update @underlying to point at the latter and let the Garbage Collector do its job to get rid of the list.
Let’s now dive in RedisSortedSet#add_list:
module BYORedis
class RedisSortedSet
# ...
private
def add_list(score, member, options: {})
raise "#{ @underlying } is not a List" unless @underlying.is_a?(List)
unless [ nil, :nx, :xx ].include?(options[:presence])
raise "Unknown presence value: #{ options[:presence] }"
end
iterator = List.left_to_right_iterator(@underlying)
while iterator.cursor
cursor = iterator.cursor
pair = iterator.cursor.value
if pair.member == member
# We found a pair in the list with a matching member
if pair.score == score && !options[:incr]
# We found an exact match, without the INCR option, so we do nothing
return false
elsif options[:presence] == :nx
# We found an element, but because of the NX option, we do nothing
return false
else
# The score changed, so we might need to reinsert the element at the correct
# location to maintain the list sorted
new_score = options[:incr] ? Utils.add_or_raise_if_nan(pair.score, score) : score
prev_node = cursor.prev_node
next_node = cursor.next_node
if (next_node.nil? ||
next_node.value.score > new_score ||
(next_node.value.score == score && next_node.value.member > member)) &&
(prev_node.nil? ||
prev_node.value.score < new_score ||
(prev_node.value.score == score && prev_node.value.member < member))
cursor.value.score = new_score
else
@underlying.remove_node(cursor)
# We add the node back, which takes care of finding the correct index
unless add_list(new_score, member)
raise 'Unexpectedly failed to re-insert node after update'
end
end
if options[:incr]
return new_score
else
# If options[:ch] == true, then we want to count this update and return true
return options[:ch]
end
end
elsif pair.score > score || (pair.score == score && pair.member > member)
# As soon as we find a node where its score is greater than the score of the
# element we're attempting to insert, we store its reference in `location` so that
# we can use insert_before_node below.
# In case of a score equality, the right side of the || above, we use the
# lexicographic order of the member value to sort them
# We cannot stop here however because there might be an exact member match later in
# the list, in which case the `if pair.member == member` check above will trigger
# and return
location ||= cursor
if options[:member_does_not_exist]
break
else
iterator.next
end
elsif pair.score < score || (pair.score == score && pair.member < member)
# In this case we haven't found a node where the score is greater than the one we're
# trying to insert, or the scores are equal but the lexicographic order tells us that
# member is greater than the current node, so we keep searching for an insert location
# to the right
iterator.next
else
# We've covered all cases, this is never expected to happen
raise "Unexpected else branch reached for #{ score }/#{ member }"
end
end
return false if options[:presence] == :xx
new_pair = Pair.new(score, member)
if location
@underlying.insert_before_node(location, new_pair)
else
@underlying.right_push(new_pair)
end
if options[:incr]
score
else
true
end
end
end
end
listing 10.9 The RedisSortedSet#add_list method
There is a lot going on in there, let’s go through all of it very slowly.
The first few lines take care of performing some sanity checks, if @underlying is not a List, we raise an exception, if options[:presence] is not one of the valid values, we also raise an exception. These cases fall in the category of “bugs”, they’re not expected, and there’s not much we could do beside reporting the error to the administrator of the server. Being so aggressive with the error handling, raising an error and letting it crash will ideally help catching these errors during the development phase.
As a quick aside, there are different philosophies with regard to how errors like this one should be handled. Redis uses the serverPanic macro in a few places such as when the encoding of what it expects to be a sorted set is neither a skiplist or ziplist. This macro ends up calling exit(3), with the argument 1, the C function that exits the current process, and 1 signifies an error, 0 is the exit code for success. In this case, we could eventually rescue the exception and return an error to the user saying something like: “Something went wrong”, similar to a web server returning a 500 HTTP response.
This would let the server running and potentially serve other requests. That being said, some errors might be severe enough that we should worry about the state of the server and crashing might be safer than letting it run, potentially returning invalid values. There are also approaches where the behavior would be different in development or debug mode versus release or production mode, where the errors would be aggressively uncaught during the development phase to increase the likelihood of a developer catching them.
This is a topic that would probably deserve its own book and as a conclusion note that the approach we’re taking here is one approach, among many others.
Next, we create a List iterator with List.left_to_right_iterator, and we start iterating in a while loop over each element in the List. We will need to inspect the neighbors of the current node below, and as we explained earlier, this is why we cannot use the new List#each method here. Each element of the list is a Pair instance, with score & member methods. If pair.member == member, it’s a match! We found a member in the sorted set that matches the one we’re trying to insert. In this case we will handle the update in the if branch and return from there, but the code in there is the most complicated part of the method, so let’s skip over it for now and we’ll get back to it later.
The next branches of the if are:
pair.score > score || (pair.score == score && pair.member > member)
and:
pair.score < score || (pair.score == score && pair.member < member)
The first one can be translated in plain English as “if the score of item under the cursor is greater than the score we’re trying to add OR if the score of the item under the cursor is the same as the score we’re trying to add but the member value, a string, of the item under the cursor is greater than the one we’re trying to add”.
This is the case where we found the direct successor of the new element, and we should insert the new pair before it. There’s a trick though! Even though it looks like we found the right place to insert the new pair in the list, this might not be true yet, we cannot know for sure at this point. If we made it to this branch, it means we have not yet found a pair with a matching member. So there are two possibilities here. Either the member is not in the set, and this is where it should be inserted, or, the member is in the set, with a greater score, further in the list. So we need to keep iterating through the list, just in case one of the elements we have not looked at yet is a match on member. The following is an example of this situation:
127.0.0.1:6379> ZADD z 10.0 a 3.0 b
(integer) 2
127.0.0.1:6379> ZRANGE z 0 -1 WITHSCORES
1) "b"
2) "3"
3) "a"
4) "10"
127.0.0.1:6379> ZADD z INCR 1 a
"11"
If we had stopped right after location ||= cursor, then we would have inserted <1, 'a'> before <3, 'b'>, and ended up with a duplicated 'a' in the set!
We use the “or equals” operator, which will only assign a value if the left operand is truthy. We might find other members in the list that have greater scores or greater members, but we still want to keep the location of the first of those to determine which node should be the successor of the one we’re trying to add.
The second elsif, pair.score < score || (pair.score == score && pair.member < member) might as well had been written as an else, but writing as such allows us to catch bugs, because this is the only condition we’d expect to happen: “if the score of the item under the cursor is lower than the score we’re trying to add, OR if the score of the item under the cursor is the same as the score we’re trying to add but the member value, a string, of the item under the cursor is lower than the one we’re trying to add”. In other words, the new member should be added the further in the list, so we need to keep looking for the correct value for location.
If we exited the loop without finding a match, and options[:presence] was set to xx, then we return false, because xx forbids the addition of new elements, and we are about to add a new element now. If options[:presence] is anything else, nil or nx, we are allowed to add new set members and we proceed to instantiating a new Pair with score and member.
Now we need to decide where to insert new_pair in the List, with the constraint that we should maintain the elements sorted by score, and member if their score values are equal. It turns out that we skipped this step, while iterating through the list, we’ll store a reference to the element that should succeed new_pair, in the location variable, and we call List#insert_before_node to add the set member.
If we failed to set a location, it means that we did not find an element that should succeed new_pair, in which case we insert it last with List#right_push.
The last step of the method is to decide what to return, if options[:incr] was set, we want to return the score of the new pair, otherwise we return true, to indicate that an element was added, which counts as a change no matter what, meaning that we count it regardless of the value of options[:ch].
The List#insert_before_node is a new one, let’s look at it:
module BYORedis
class List
# ...
def insert_before_node(pivot_node, element)
new_node = ListNode.new(element, pivot_node.prev_node, pivot_node)
if @head == pivot_node
@head = new_node
else
pivot_node.prev_node.next_node = new_node
end
pivot_node.prev_node = new_node
@size += 1
end
def insert_before(pivot, element)
generic_insert(pivot) do |node|
insert_before_node(node, element)
end
end
def insert_after(pivot, element)
generic_insert(pivot) do |node|
new_node = ListNode.new(element, node, node.next_node)
if @tail == node
@tail = new_node
else
node.next_node.prev_node = new_node
end
node.next_node = new_node
@size += 1
end
end
# ...
private
def generic_insert(pivot)
cursor = @head
while cursor
break if cursor.value == pivot
cursor = cursor.next_node
end
if cursor.nil?
-1
else
yield cursor
@size
end
end
end
end
listing 10.10 The insert_before_node refactor in the List class
We use to be able to only have insert_before and insert_after, which both operate based on a pivot value, which they look for in the list. Both were initially created for the LINSERT command. But while we could still use insert_before here, it would be wasteful to start iterating from the start of the list if we already had a reference to the node we wanted to use as the insertion point.
So this is what this refactor is about, insert_before and insert_after still have the same behavior, but insert_before is now written in terms of insert_before_node, a new method containing code that used to be in insert_before. We used to increment the @size instance variable in generic_insert, but because insert_before_node does not call it, we need to move it to make sure that calling either of three insert methods correctly increment the instance variable.
Let’s go back to RedisSortedSet#add, inside the while loop, inside the if pair.member == member condition. We first check if pair.score == score, in which case we found an exact match, there is a member in the set with the same score and the same member, which means that we usually have nothing to do, except if option[:incr] is set. In which case it doesn’t matter what the current score is, we want to add the value in the score argument to the score that was already in the set.
Next, if options[:presence] == :nx, then updates are forbidden, we’re only allowed to add new elements, and since we found a match on member, we can return early, since we’re about to update the existing pair.
One more else branch, hang in there with me. We now need to perform an update, we found the node in the list that contains the member, but there are a few different possibilities depending on the values in options.
First, we compute the new score, if options[:incr] is true, then we need to add the existing score to the new one, but we need to watch out for “invalid float values”. What is an “invalid float value” you ask? Let’s look at an example:
irb(main):001:0> require 'bigdecimal'
=> true
irb(main):002:0> inf = BigDecimal::INFINITY
irb(main):003:0> inf + inf
=> Infinity
irb(main):004:0> inf - inf
=> NaN
We can’t subtract inf from inf, it’s Not a Number, let’s confirm this in redis:
127.0.0.1:6379> ZADD z INCR inf a
"inf"
127.0.0.1:6379> ZADD z INCR -inf a
(error) ERR resulting score is not a number (NaN)
We handle this with the Utils.add_or_raise_if_nan method:
module BYORedis
# ...
IntegerOverflow = Class.new(StandardError)
FloatNaN = Class.new(StandardError)
InvalidIntegerString = Class.new(StandardError)
InvalidFloatString = Class.new(StandardError)
module Utils
# ...
def self.add_or_raise_if_nan(a, b)
BigDecimal.save_exception_mode do
BigDecimal.mode(BigDecimal::EXCEPTION_NaN, true)
a + b
end
rescue FloatDomainError
raise FloatNaN
end
end
end
listing 10.11 The Utils.add_or_raise_if_nan method
We use the save_exception_mode so that we don’t modify the behavior of BigDecimal operations once we’re done here, and if it does raise an exception, FloatDomainError, we convert it to our own exception, FloatNaN, which we added at the top of the utils.rb file.
If we’re not in increment mode, then the new score is the score argument, we override what was there before.
So now, we have the new score, we need to update it, we could change the value in the list node with cursor.value.score = new_score, but how do we know if the node will still be where it should be in the list once the score is updated? Well, we can check for it. This is what this weird looking condition does:
If there is no next node, the current node is the last one, or if there is a next node, and that next node score is greater than the updated score of the current node, or if the scores are equal but the next node’s member string is greater than the string of the current member
AND
If there is no previous node, the current node is the first one, or if there is a previous node, and that previous node score is lower than the updated score of the current node, or if the scores are equal but the previous node’s member string is lower than the string of the current member
THEN
The list will still be in order after the score update
If this condition fails, the current node will not be in the right place after the score update. Instead of trying to find the correct location, we remove the node and call RedisSortedSet#add again, with the new score, and we know it won’t find the member so we pass the member_does_not_exist option to break right after location ||= cursor, to prevent a full iteration of the list:
# ...
elsif pair.score > score || (pair.score == score && pair.member > member)
# ...
location ||= cursor
if options[:member_does_not_exist]
break
else
iterator.next
end
elsif pair.score < score # ...
# ...
listing 10.12 The member_does_not_exist option handling in the RedisSortedSet#add_list method
Done! That’s it, we can add members to a sorted set … as long as it uses a List under the hood, we need to handle the other case, when the strings are either too big, or the sorted set contains too many entries.
Adding Members to a ZSet
Luckily the process is not as complicated in a ZSet, thanks the easier lookup in a Dict. Let’s create the ZSet#add method:
module BYORedis
class ZSet
# ...
def add(score, member, options)
unless [ nil, :nx, :xx ].include?(options[:presence])
raise "Unknown presence value: #{ options[:presence] }"
end
entry = @dict.get_entry(member)
if entry
return false if options[:presence] == :nx
if entry.value != score || options[:incr]
existing_pair = new_pair(entry.value, member)
index = @array.index(existing_pair)
if index.nil?
raise "Failed to find #{ member }/#{ entry.value } in #{ @array.inspect }"
end
array_element = @array[index]
while array_element.member != member && index < @array.size
index += 1
array_element = @array[index]
end
if index == @array.size
raise "Failed to find #{ member }/#{ entry.value } in #{ @array.inspect }"
end
new_score = options[:incr] ? Utils.add_or_raise_if_nan(entry.value, score) : score
next_member = @array[index + 1]
prev_member = @array[index - 1]
if (next_member.nil? ||
next_member.score > new_score ||
(next_member.score == new_score && next_member.member > member)) &&
(prev_member.nil? ||
prev_member.score < new_score ||
(prev_member.score == new_score && prev_member.member < member))
array_element.score = new_score
else
@array.delete_at(index)
@array << new_pair(new_score, member)
end
entry.value = new_score
end
if options[:incr]
new_score
else
options[:ch] # false by default
end
else
return false if options[:presence] == :xx
@array << new_pair(score, member)
@dict[member] = score
if options[:incr]
score
else
true
end
end
end
private
def new_pair(score, member)
RedisSortedSet::Pair.new(score, member)
end
end
end
listing 10.13 The ZSet#add method
First we use the Dict#get_entry method to check for the existence of member in the sorted set. Things are already simpler here, we don’t have to iterate over anything to determine the presence of the member we’re trying to add or update.
If we found a match but options[:presence] is set to :nx then updates are forbidden and we can stop right away by returning false.
If the score value of the existing member is the same as the one we’re trying to add, there’s nothing to do, the update would be a no-op, except if options[:incr] is set to true, in which case we want to sum the existing score and the new one. This is what we check with if entry.value != score || options[:incr], if this condition is true, we do want to update the score of the existing member.
entry is the result of calling Dict#get_entry and is a DictEntry instance where key is the score and value is the member. We create an instance of Pair to facilitate the interaction with the SortedArray, such as calling SortedArray#index to find the position of the pair in the sorted set.
We always expect to find the pair in the sorted array, because we do the bookkeeping work necessary to maintain the consistency between the Dict and the SortedArray, but it is technically possible that SortedArray#index returns nil, and in this case we throw an exception. This is another instance of a case that falls in the category of “bugs”, unexpected situations where there’s nothing we can really do, and we might as well notify the administrator of the server with a crash and hope that these bugs would be caught in the development phase.
The next check is pure paranoia and could be considered useless, but we double check that the value at index index is indeed equal to existing_pair. Since returning the index for the given value is the contract of the SortedArray#index method you might wonder why we’d want to perform it. The main reason here is that such check is “cheap” in the sense of it not requiring a lot of extra instructions, and it would catch obvious bugs in the SortedArray#index method, so why not!
Back to the add method, we’re using Utils.add_or_raise_if_nan similarly to how we did in the List case, to handle cases such as inf - inf. Next we perform the same check to see if the existing member’s position in the sorted array will still be correct after the update. We compare it with the next and previous elements in the array, if they exist.
If the order would not be broken, then we update the Pair instance, otherwise we delete it with SortedArray#delete_at, which is delegated to Array#delete_at and we insert it again, letting the SortedArray class find the new position.
Finally, we update the value in Dict with entry.value = new_score.
The return value after an update depends on the values of options[:incr] and options[:ch]. As we’ve seen earlier, the INCR option takes precedence, in which case we return the new score, otherwise we return false by default, if it was an update, or true, if the CH option was used and updates should be counted.
The else branch handles the case where the member does not exist in the set, in which case we return false early if the XX option was used, forbidding adding members and only allowing updates. Otherwise, we add the Pair instance to the sorted array and add the score and member to the Dict. We use a logic similar to what we just did to determine the return value, except that regardless of the presence or not of the CH option, we always return true as additions always count as changes.
And here we are! The ZADD command works!
Counting members in a Sorted Set
Now that we added the ability to create sorted sets and to add new members to them, let’s add the ZCARD command to count the number of members in a sorted set:
module BYORedis
# ...
class ZCardCommand < BaseCommand
def call
Utils.assert_args_length(1, @args)
sorted_set = @db.lookup_sorted_set(@args[0])
cardinality = sorted_set&.cardinality || 0
RESPInteger.new(cardinality)
end
def self.describe
Describe.new('zcard', 2, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.14 The ZCardCommand class
We call the cardinality method on the RedisSortedSet instance, with the “safe navigation” operator, &., which returns nil if sorted_set itself is nil, which would then take us to the right side of the || operator and effectively default cardinality to 0. Let’s add the RedisSortedSet#cardinality method:
module BYORedis
class RedisSortedSet
# ...
def cardinality
case @underlying
when List then @underlying.size
when ZSet then @underlying.cardinality
else raise "Unknown type for #{ @underlying }"
end
end
# ...
end
end
listing 10.15 The RedisSortedSet#cardinality method
In the List case we return the result of calling List.size, and for a ZSet, we need to add the cardinality method to the class:
module BYORedis
class ZSet
# ...
def cardinality
@array.size
end
end
end
listing 10.16 The ZSet#cardinality method
We could have included Forwardable and used it to delegate #size to @array, but there’s only one method we need to directly delegate, so the “cost” of manually doing the delegation is really small compared to the “complexity” of including a module, and calling def_delegators, which doesn’t save us much for only one method.
This wraps up the first two commands for sorted sets, ZADD & ZCARD, next we’ll look at the different range commands.
Reading from Sorted Sets
With ZADD implemented, we will now add commands to retrieve elements from sorted sets. We’ve already seen the ZRANGE command, but Redis provides two more similar commands, ZRANGEBYSCORE & ZRANGEBYLEX.
Re-using the sorted set z from earlier in the chapter, we can use ZRANGEBYSCORE to only select a range of members within the given score, whereas ZRANGE returns member depending on their index in the sorted set, their rank. If ZRANGE had a more explicit name it’d be called ZRANGEBYRANK.
127.0.0.1:6379> ZRANGEBYSCORE z 0 1
1) "zero"
127.0.0.1:6379> ZRANGEBYSCORE z 0 3
1) "zero"
2) "a"
3) "aa"
4) "aaa"
5) "ab"
6) "b"
127.0.0.1:6379> ZRANGEBYSCORE z 0 3 WITHSCORES
1) "zero"
2) "0"
3) "a"
4) "1.1000000000000001"
5) "aa"
6) "1.1000000000000001"
7) "aaa"
8) "1.1000000000000001"
9) "ab"
10) "1.1000000000000001"
11) "b"
12) "2.2000000000000002"
The equivalent of ZRANGE z 0 -1, that is, “return all the members” is ZRANGE z -inf +inf. This works because all possible values, including -inf, are greater than or equal to -inf, and all possible values, including +inf are lower than or equal to +inf.
127.0.0.1:6379> ZRANGEBYSCORE z -inf +inf
1) "zero"
2) "a"
3) "aa"
4) "aaa"
5) "ab"
6) "b"
7) "c"
8) "d"
9) "e"
10) "f"
ZRANGEBYLEX is the first command of the *BYLEX category of sorted set commands. The other ones are ZREMRANGEBYLEX and ZREVRANGEBYLEX. These three commands are meant to be used for a sorted set containing elements with identical scores. A common pattern is to set a score value of 0, but any score would work, as long as it is the same across all members. “LEX” is short for “lexicographic”, which is a fancy term for “alphabetically”, or what you would expects words to be sorted by in a dictionnary, the real kind, with word definitions, not the data structure. Both words are not absolutely equivalent, but they’re equivalent enough for the sake of this explanation.
The reason why these three commands require an identical score is because they only operate with the lexicographic order of the member values, but if scores where different, we’d have no guarantees that all members would be sorted in lexicographical order. Let’s look at an example where all scores are the same first:
127.0.0.1:6379> ZADD lex-zset 0 a 0 b 0 c 0 xylophone 0 zebra 0 something-else
(integer) 6
127.0.0.1:6379> ZRANGE lex-zset 0 -1
1) "a"
2) "b"
3) "c"
4) "something-else"
5) "xylophone"
6) "zebra"
All the scores are identical, so the lexicographic order is used as a “tiebreaker” to sort the members in the sorted set. Now let’s look at the same set of members, but with different scores:
127.0.0.1:6379> ZADD lex-zset-with-scores 1 a 0 b 18 c 3.14 xylophone 1.414 zebra 0.01 something-else
(integer) 6
127.0.0.1:6379> ZRANGE lex-zset-with-scores 0 -1
1) "b"
2) "something-else"
3) "a"
4) "zebra"
5) "xylophone"
6) "c"
127.0.0.1:6379> ZRANGE lex-zset-with-scores 0 -1 WITHSCORES
1) "b"
2) "0"
3) "something-else"
4) "0.01"
5) "a"
6) "1"
7) "zebra"
8) "1.4139999999999999"
9) "xylophone"
10) "3.1400000000000001"
11) "c"
12) "18"
The ordering by score takes precedence, and the set is not sorted alphabetically anymore.
Redis does not check that the members in the sorted set all have the same score when using a *BYLEX command, it will instead incorrect results, so it is up to the caller to make sure that the data is correctly inserted before using these commands. We can use ZRANGEBYLEX to select members within the given lexicographic range, where [ means inclusive and ( exclusive:
127.0.0.1:6379> ZRANGEBYLEX lex-zset [s [zebra
1) "something-else"
2) "xylophone"
3) "zebra"
127.0.0.1:6379> ZRANGEBYLEX lex-zset [s (zebra
1) "something-else"
2) "xylophone"
The special values - and + can be used to express values that are respectively lower than any other values and greater than any other values:
127.0.0.1:6379> ZRANGEBYLEX lex-zset [s +
1) "something-else"
2) "xylophone"
3) "zebra"
127.0.0.1:6379> ZRANGEBYLEX lex-zset - [s
1) "a"
2) "b"
3) "c"
Let’s look at the same commands, but with our other sorted set, lex-zset-with-scores:
127.0.0.1:6379> ZRANGEBYLEX lex-zset-with-scores - [s
1) "b"
127.0.0.1:6379> ZRANGEBYLEX lex-zset-with-scores [s +
(empty array)
127.0.0.1:6379> ZRANGEBYLEX lex-zset-with-scores [s [zebra
(empty array)
127.0.0.1:6379> ZRANGEBYLEX lex-zset-with-scores [s (zebra
(empty array)
The behavior is undefined, Redis makes the assumption that all elements are ordered alphabetically, since they’re not, the result is nonsensical.
A final word on lexicographic order, while it may look intuitive at first, the letter a comes before the letter b, it can be surprising when applied to numbers represented as strings, let’s look at example in Ruby first:
irb(main):010:0> '10' < '2'
=> true
The string '2' is considered to be greater than the string '10', that’s because with lexicographic order, we compare strings one character at a time, and '1' < '2' is true, so the '0' character in '10' is never even considered here.
An example that might help is to use letters instead:
irb(main):011:0> 'ba' < 'c'
=> true
a, b and c are the ASCII representation of the bytes 97, 98 and 99.
This example is very similar to the previous one, given that the byte '1' has the value 49, '0', 48 and '2', 50. We’re comparing two bytes on the left, with one on the right, on the left with have 49 and 48 and on the right we have 50. 50 is greater than 49, so we know which string is greater.
By Rank
We are going to start with the ZRANGE command. We already know that we’re going to implement a very similar command later on, ZREVRANGE, so let’s already create a method implementing the shared logic in SortedSetUtils.
The ZRANGE command has the following format according to the Redis documentation:
ZRANGE key start stop [WITHSCORES]
module BYORedis
module SortedSetUtils
# ...
def self.generic_range(db, args, reverse: false)
Utils.assert_args_length_greater_than(2, args)
start = Utils.validate_integer(args[1])
stop = Utils.validate_integer(args[2])
raise RESPSyntaxError if args.length > 4
if args[3]
if args[3].downcase == 'withscores'
withscores = true
else
raise RESPSyntaxError
end
end
sorted_set = db.lookup_sorted_set(args[0])
if reverse
tmp = reverse_range_index(start, sorted_set.cardinality - 1)
start = reverse_range_index(stop, sorted_set.cardinality - 1)
stop = tmp
end
if sorted_set
range_spec =
RedisSortedSet::GenericRangeSpec.rank_range_spec(start, stop, sorted_set.cardinality)
SortedSetRankSerializer.new(
sorted_set,
range_spec,
withscores: withscores,
reverse: reverse,
)
else
EmptyArrayInstance
end
end
end
# ...
class ZRangeCommand < BaseCommand
def call
SortedSetUtils.generic_range(@db, @args)
end
def self.describe
Describe.new('zrange', -4, [ 'readonly' ], 1, 1, 1, [ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.17 The ZRangeCommand class
The SortedSetUtils.generic_range method implements the range logic, including validating the arguments and uses the SortedSetRankSerializer class to serialize the result
Let’s now look at the serializer class, as well as the “range spec” class, GenericRankRangeSpec. We’ll make use of other type of range specs throughout this chapter, for score order and lexicographic order, when implementing other range related commands.
This range spec class encapsulates all the data required to define a rank spec, that is, a minimum value and a maximum value, both Integer instances. We also pass the set cardinality to the class to let it transform negative indices into actual indices. For example, -1, becomes cardinality - 1, the index of the last item in the set, -2 becomes cardinality - 2, the second to last index, and so on. The rank_range_spec also makes sure that the final values of min and max are not outside the range of valid indices, that is min cannot be lower than 0 and max cannot be greater than or equal to cardinality, because there are no elements with such ranks.
The range spec also defines a useful method, empty?, when the range cannot possibly include any elements, for instance the range 1..0 in Ruby is empty, as we can see with the result of calling .to_a on it, an empty array:
irb(main):034:0> (1..0).to_a
=> []
The comparison logic relies on “comparison values” that we’ve explored we discussing the uses of the bsearch_index method, -1 means that the first of the two items being compared is lower than the second one, 0 means they’re equal and 1 means that the second one is greater. Using this approach will allow us to customize the actual comparison logic while still reusing the core methods of this class.
The actual comparison function used by the GenericRangeSpec is the block argument given to its constructor, in this case use a <=> b, the expected order of integers.
module BYORedis
class RedisSortedSet
# ...
class GenericRangeSpec
attr_reader :min, :max, :min_exclusive, :max_exclusive
alias min_exclusive? min_exclusive
alias max_exclusive? max_exclusive
def self.rank_range_spec(min, max, cardinality)
max = cardinality + max if max < 0
min = cardinality + min if min < 0
max = cardinality - 1 if max >= cardinality
min = 0 if min < 0
GenericRangeSpec.new(min, max, false, false) do |a, b|
a <=> b
end
end
def initialize(min, max, min_exclusive, max_exclusive, &block)
@min = min
@min_exclusive = min_exclusive
@max = max
@max_exclusive = max_exclusive
@block = block
end
def empty?
comparison = compare_with_max(min)
comparison > 0 || (comparison == 0 && (min_exclusive? || max_exclusive?))
end
def compare_with_max(element)
@block.call(element, @max)
end
end
# ...
end
class SortedSetRankSerializer
def initialize(sorted_set, range_spec, withscores: false, reverse: false)
@sorted_set = sorted_set
@range_spec = range_spec
@withscores = withscores
@reverse = reverse
end
def serialize
return RESPArray.new([]).serialize if @range_spec.empty?
case @sorted_set.underlying
when List then serialize_list
when ZSet then serialize_zset
else raise "Unknown type for #{ @underlying }"
end
end
private
def serialize_zset
members = []
(@range_spec.min..@range_spec.max).each do |rank|
pair = @sorted_set.underlying.array[rank]
if @reverse
members.prepend(Utils.float_to_string(pair.score)) if @withscores
members.prepend(pair.member)
else
members.push(pair.member)
members.push(Utils.float_to_string(pair.score)) if @withscores
end
end
RESPArray.new(members).serialize
end
def serialize_list
ltr_acc = lambda do |value, response|
response << RESPBulkString.new(value.member).serialize
if @withscores
response << RESPBulkString.new(Utils.float_to_string(value.score)).serialize
end
@withscores ? 2 : 1
end
rtl_acc = lambda do |value, response|
if @withscores
response.prepend(RESPBulkString.new(Utils.float_to_string(value.score)).serialize)
end
response.prepend(RESPBulkString.new(value.member).serialize)
@withscores ? 2 : 1
end
if @reverse
tmp = ltr_acc
ltr_acc = rtl_acc
rtl_acc = tmp
end
ListSerializer.new(@sorted_set.underlying, @range_spec.min, @range_spec.max)
.serialize_with_accumulators(ltr_acc, rtl_acc)
end
end
end
listing 10.18 The SortedSetRankSerializer class
The serialize method calls serialize_list or serialize_zset depending on the type of @underlying. Let’s first look look at the ZSet case, we can leverage the array structure inside the ZSet to extract the range of elements we need, based on on min and max attribute of the range spec.
The score values should only be included if the WITHSCORES option was set. Additionally, the order of the final array depends on the requested order. We’re jumping ahead a little bit here, but we can already assume that the ZREVRANGE method will be very similar to the ZRANGE method. So for now reverse is always set to false, meaning that for each pair in the set we always append the member value, and conditionally add the score value afterward.
Once the members array is created, we serialize it as a RESPArray.
In the List case, we use a new method from the ListSerializer class, serialize_with_accumulators:
module BYORedis
# ...
class ListSerializer
def initialize(list, start, stop)
@list = list
@start = start
@stop = stop
end
def serialize_with_accumulators(left_to_right_accumulator, right_to_left_accumulator)
@stop = @list.size + @stop if @stop < 0
@start = @list.size + @start if @start < 0
@stop = @list.size - 1 if @stop >= @list.size
@start = 0 if @start < 0
return EmptyArrayInstance.serialize if @start > @stop
response = ''
size = 0
distance_to_head = @start
distance_to_tail = @list.size - @stop
if distance_to_head <= distance_to_tail
iterator = List.left_to_right_iterator(@list)
within_bounds = ->(index) { index >= @start }
stop_condition = ->(index) { index > @stop }
accumulator = left_to_right_accumulator
else
iterator = List.right_to_left_iterator(@list)
within_bounds = ->(index) { index <= @stop }
stop_condition = ->(index) { index < @start }
accumulator = right_to_left_accumulator
end
until stop_condition.call(iterator.index)
if within_bounds.call(iterator.index)
size += accumulator.call(iterator.cursor.value, response)
end
iterator.next
end
response.prepend("*#{ size }\r\n")
end
def serialize
serialize_with_accumulators(
lambda do |value, response|
response << RESPBulkString.new(value).serialize
1
end,
lambda do |value, response|
response.prepend(RESPBulkString.new(value).serialize)
1
end,
)
end
end
end
listing 10.19 Updates to the ListSerializer class
We extracted most of the serialize method to the new serialize_with_accumulators method, which allows us to use the same overall logic, while being able to serialize individual list nodes differently. This is what we do in the SortedSetRankSerializer#serialize_list method.
Back to the serialize_list method in SortedSetRankSerializer, we create two different accumulators that are aware of the @withscores value and can decide whether or not to include it in the final serialized string when iterating over the list for serialization.
As a reminder, we give both a “left to right” and a “right to left” accumulator to ListSerializer so that it can use the most efficient way to serialize the list. Depending on the range it needs to serialize, it might decide to iterate from the right, if it’ll be faster to find the range in the list.
Each of the accumulators now return an integer representing the number of elements added to the final response. This is necessary because the WITHSCORES option will force us to add two items in the final response for each item in the list, the member attribute, followed by the score attribute.
When iterating from the left, we’ll encounter items in the order we want them to be in the final array, so we can first append the member value to response, and then, conditionally, append the score value. On the other hand, if we’re iterating from right to left, we’ll encounter items in the opposite order we want them to be in the final array, so we first, conditionally, prepend the score value, and then, always, prepend the member value. Let’s look at an example with a small array to illustrate this.
If we have the array [ [ 10, 'a' ] , [ 20, 'b' ], [ 30, 'c' ], [ 40, 'd' ], [ 50, 'e' ] ], and we’re requesting the range 1, 2, we should return the array [ 'b', 20, 'c', 30 ]. If we were requesting the range 2, 3, we should return the array [ 'c', 30, 'd', 40 ].
If we’re iterating from left to right, as would be case with the range 1, 2, since it’s faster to reach it from the left side, we would first encounter [ 20, 'b' ], and then [ 30, 'c' ], so we can append elements as we go, in the same order as the desired final order, member first, score, second.
On the other hand, if we’re iterating from right to left, as would be the case with the range 2, 3, because it’s faster to reach from the right side, we would first encounter [ 'd', 40 ] and then [ 'c', 30 ]. So when reaching the first element, we would first prepend the score and then the member, giving us the array [ 'd', 40 ], and we would do the same with the second pair, prepending 30, and then prepending 'c', giving us the desired result [ 'c', 30, 'd', 40 ].
As we did earlier, we can ignore the @reverse branch, that’ll only be needed for the ZREVRANGE method.
By Score
Let’s now add the ZRANGEBYSCORE command, which has the following format according to the Redis doc:
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
min and max are a new type of range, a “score range”, which we’ll also represent with the GenericRangeSpec class.
Both values must be valid floats, that includes the values -inf and +inf, which happen to be the equivalent of 0 and -1 in the ZRANGE command, that is, a way to ask for all the elements in the sorted set:
127.0.0.1:6379> ZADD z 0.1 a 2 b 3.2 c -10 d
(integer) 4
127.0.0.1:6379> ZRANGEBYSCORE z -inf +inf
1) "d"
2) "a"
3) "b"
4) "c"
By default the values are considered inclusive, but this can be controlled with the prefix ( to mark it as exclusive, let’s look at an example with the previous sorted set, z:
127.0.0.1:6379> ZRANGEBYSCORE z -inf 2
1) "d"
2) "a"
3) "b"
127.0.0.1:6379> ZRANGEBYSCORE z -inf (2
1) "d"
2) "a"
LIMIT and OFFSET are used to respectively limit the number of elements in the result and skip an arbitrary number of elements. A negative count value is the same as not passing a value and means “return all matches”, negative offsets are accepted but will always result in an empty array.
Let’s go ahead and add all that in sorted_set_commands.rb:
module BYORedis
module SortedSetUtils
def self.generic_range_by_score(db, args, reverse: false)
# A negative count means "all of them"
options = { offset: 0, count: -1, withscores: false }
Utils.assert_args_length_greater_than(2, args)
key = args.shift
if reverse
max = args.shift
min = args.shift
else
min = args.shift
max = args.shift
end
range_spec = Utils.validate_score_range_spec(min, max)
parse_range_by_score_options(args, options) unless args.empty?
sorted_set = db.lookup_sorted_set(key)
if options[:offset] < 0
EmptyArrayInstance
elsif sorted_set
options[:reverse] = reverse
SortedSetSerializerBy.new(sorted_set, range_spec, **options, &:score)
else
EmptyArrayInstance
end
end
def self.parse_limit_option(args, options)
offset = args.shift
count = args.shift
raise RESPSyntaxError if offset.nil? || count.nil?
offset = Utils.validate_integer(offset)
count = Utils.validate_integer(count)
options[:offset] = offset
options[:count] = count
end
def self.parse_range_by_score_options(args, options)
while arg = args.shift
case arg.downcase
when 'withscores' then options[:withscores] = true
when 'limit' then SortedSetUtils.parse_limit_option(args, options)
else raise RESPSyntaxError
end
end
end
# ...
end
# ...
class ZRangeByScoreCommand < BaseCommand
def call
SortedSetUtils.generic_range_by_score(@db, @args, reverse: false)
end
def self.describe
Describe.new('zrangebyscore', -4, [ 'readonly' ], 1, 1, 1,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.20 The ZRangeByScoreCommand class
We’re again anticipating the upcoming reverse command, ZREVRANGEBYSCORE in this case, and create generic_range_by_score to share the common logic, for now reverse is always false, so we can ignore the branches where it handles the true case.
We need to add the validate_score_range_spec method to the Utils module:
module BYORedis
module Utils
# ...
def self.validate_score_range_spec(min, max)
min, min_exclusive = parse_score_range_item(min)
max, max_exclusive = parse_score_range_item(max)
RedisSortedSet::GenericRangeSpec.score_range_spec(
min, max, min_exclusive, max_exclusive)
end
def self.parse_score_range_item(str)
if str[0] == '('
str = str[1..-1]
exclusive = true
else
exclusive = false
end
return validate_float(str, 'ERR min or max is not a float'), exclusive
end
private_class_method :parse_score_range_item
end
end
listing 10.21 The Utils.validate_score_range_spec method
The new method in the Utils module, validate_score_range_spec, takes care of creating an instance of GenericRangeSpec, with the correct exclusive flags set depending on the presence of (. Let’s add a method to create a range spec with the appropriate comparison function, passed as a block. We’re also adding a new method, no_overlap_with_range? which will be used to determine when we can avoid to do any work if we can determine that no items match the requested range.
module BYORedis
class RedisSortedSet
# ...
class GenericRangeSpec
attr_reader :min, :max, :min_exclusive, :max_exclusive
alias min_exclusive? min_exclusive
alias max_exclusive? max_exclusive
def self.score_range_spec(min, max, min_exclusive, max_exclusive)
GenericRangeSpec.new(min, max, min_exclusive, max_exclusive) do |a, b|
a <=> b
end
end
# ...
end
# ...
def no_overlap_with_range?(range_spec, &block)
# Note that in that each condition the "value" is abstract and determined by the return
# value of calling the block variable, in practice it's either score, member, or rank
# There is no overlap under the four following conditions:
# 1. the range spec min is greater than the max value:
# set : |---|
# range: |---| (min can be inclusive or exclusive, doesn't matter)
# 2. the range spec min is exclusive and is equal to the max value
# set : |---|
# range: (---| (min is exclusive)
# 3. the min value is greater than range spec max
# set : |---|
# range: |---| (max can be inclusive or exclusive, doesn't matter)
# 4. the min value is equal to the range spec max which is exclusive
# set : |---|
# range: |---( (max is exclusive)
max_pair, max_pair_rank = max_pair_with_rank
min_pair, min_pair_rank = min_pair_with_rank
set_max_range_spec_min_comparison =
range_spec.compare_with_min(block.call(max_pair, max_pair_rank))
set_min_range_spec_max_comparison =
range_spec.compare_with_max(block.call(min_pair, min_pair_rank))
set_max_range_spec_min_comparison == -1 || # case 1
(range_spec.min_exclusive? && set_max_range_spec_min_comparison == 0) || # case 2
set_min_range_spec_max_comparison == 1 || # case 3
(range_spec.max_exclusive? && set_min_range_spec_max_comparison == 0) # case 4
end
private
# @return [Array] Two values, the first is a Pair, and the second is the rank
def max_pair_with_rank
case @underlying
when List
return @underlying.tail.value, @underlying.size
when ZSet
return @underlying.array[-1], @underlying.array.size - 1
else raise "Unknown type for #{ @underlying }"
end
end
# @return [Array] Two values, the first is a Pair, and the second is the rank
def min_pair_with_rank
case @underlying
when List
return @underlying.head.value, 0
when ZSet
return @underlying.array[0], 0
else raise "Unknown type for #{ @underlying }"
end
end
# ...
end
# ...
end
listing 10.22 The score_range_spec and no_overlap_with_range? methods
The new class method on GenericRangeSpec allows us to create a range specific to score ranges, which handles the exclusive boundaries.
The score_range_spec class method is almost identical to the rank_range_spec one from earlier, with the difference that it doesn’t have to handle negative values, it just takes the score boundaries as in, as well as the exclusivity flags, which is something that we did not have to consider in the rank case, but the comparison of elements is the same, we’re comparing numbers, Integer instances for ranks, BigDecimal instances for scores, and both can be compared with <=>, which is defined on both: Integer#<=> and BigDecimal#<=>.
If either of the boundaries is flagged as exclusive, then the range will be empty if they’re equal. Looking at a Ruby example illustrates this pretty clearly:
irb(main):006:0> (0..0).to_a
=> [0]
irb(main):007:0> (0...0).to_a
=> []
The triple period notation is the exclusive range notation in Ruby, and as we can see the range “0 to 0, exclusive” is empty.
If neither of the boundaries is flagged as exclusive, then the only condition making the range empty is if min is greater than max, that is if the value of comparison is 1.
If either of the boundaries is marked as exclusive then a comparison result of 0, meaning equality, is enough to flag the range as empty.
This is the logic that is implemented in the empty? method. Let’s also add the in_range? method so we can check for the inclusivity of an element in the range with awareness of the exclusivity of the min and max boundaries:
module BYORedis
class RedisSortedSet
# ...
class GenericRangeSpec
# ...
def empty?
comparison = compare_with_max(min)
comparison > 0 || (comparison == 0 && (min_exclusive? || max_exclusive?))
end
def compare_with_min(element)
@block.call(element, @min)
end
def in_range?(element)
return false if empty?
comparison_min = compare_with_min(element)
comparison_max = compare_with_max(element)
comparison_min_ok = min_exclusive? ? comparison_min == 1 : comparison_min >= 0
comparison_max_ok = max_exclusive? ? comparison_max == -1 : comparison_max <= 0
comparison_min_ok && comparison_max_ok
end
end
# ...
end
end
listing 10.23 The empty?, compare_with_min & in_range? methods for the GenericRangeSpec class
We can now use the same class for our different use cases, rank ranges and score ranges, let’s quickly play with it in irb:
irb(main):001:0> require_relative './redis_sorted_set'
=> true
irb(main):002:0> range_spec_class = BYORedis::RedisSortedSet::GenericRangeSpec
irb(main):003:0> rank_range_spec = range_spec_class.rank_range_spec(2, 3, 10)
irb(main):004:0> rank_range_spec.in_range?(1)
=> false
irb(main):005:0> rank_range_spec.in_range?(4)
=> false
irb(main):006:0> rank_range_spec.in_range?(3)
=> true
irb(main):007:0> rank_range_spec = range_spec_class.rank_range_spec(2, -1, 10)
irb(main):008:0> rank_range_spec.in_range?(9)
=> true
irb(main):009:0> rank_range_spec.in_range?(10)
=> false
irb(main):010:0> score_range_spec = range_spec_class.score_range_spec(2, 10, true, false)
irb(main):011:0> score_range_spec.in_range?(2)
=> false
irb(main):012:0> score_range_spec.in_range?(2.1)
=> true
irb(main):013:0> score_range_spec.in_range?(10)
=> true
1 & 4 are out of range for the rank range spec 2, 3 within a set of size 10, that makes sense, only 2 and 3 are in range. We can see the transformation of negative indices when using the range 2, -1 in a set of size 10, the last rank is 9, the 0-based index of the last element, so 9 is in range, and 10 is not.
Switching to a score range, the last two boolean values determine the exclusivity of respectively the min and max boundaries, so the range we create is (2 10. We can see that 2 is out of range and 2.1 is in range, 10 is as well.
We created the range_spec_class variable only for convenience within the irb session.
Equipped with our new range spec constructor wrapper to create score range specs, the final class we need to add for this command is SortedSetSerializerBy:
module BYORedis
# ...
class SortedSetSerializerBy
def initialize(sorted_set, range_spec,
offset: 0, count: -1, withscores: false, reverse: false, &block)
@sorted_set = sorted_set
@range_spec = range_spec
@offset = offset
@count = count
@withscores = withscores
@reverse = reverse
if block.arity != 2
@block = proc { |element, _| block.call(element) }
else
@block = block
end
end
def serialize
if @offset < 0 ||
@range_spec.empty? ||
@sorted_set.no_overlap_with_range?(@range_spec, &@block)
return RESPArray.new([]).serialize
end
case @sorted_set.underlying
when List then serialize_list
when ZSet then serialize_zset
else raise "Unknown type for #{ @underlying }"
end
end
private
def serialize_zset
members = []
if @reverse
start_index = @sorted_set.underlying.array.last_index_in_range(@range_spec, &@block)
if start_index.nil?
raise "Unexpectedly failed to find last index in range for #{ self }"
end
indices = start_index.downto(0)
else
start_index = @sorted_set.underlying.array.first_index_in_range(@range_spec, &@block)
if start_index.nil?
raise "Unexpectedly failed to find first index in range for #{ self }"
end
indices = start_index.upto(@sorted_set.cardinality - 1)
end
indices.each do |i|
item = @sorted_set.underlying.array[i]
if @range_spec.in_range?(@block.call(item))
if @offset == 0
members << item.member
members << Utils.float_to_string(item.score) if @withscores
@count -= 1
break if @count == 0
else
@offset -= 1
end
else
break
end
end
RESPArray.new(members).serialize
end
def serialize_list
if @reverse
iterator = List.right_to_left_iterator(@sorted_set.underlying)
else
iterator = List.left_to_right_iterator(@sorted_set.underlying)
end
members = []
entered_range = false
while iterator.cursor && @count != 0
member = iterator.cursor.value
if @range_spec.in_range?(@block.call(member))
entered_range ||= true
if @offset == 0
members << member.member
members << Utils.float_to_string(member.score) if @withscores
@count -= 1
else
@offset -= 1
end
elsif entered_range == true
break
end
iterator.next
end
RESPArray.new(members).serialize
end
end
end
listing 10.24 The serialize_zset & serialize_list methods for the SortedSetSerializerBy class
We start the serialize methods with three checks to return early if we can. In the first one, we test if the offset value is negative, if it is, we can return an empty array. We can also return early if the range is empty, or if the range and the set don’t overlap.
Let’s take a closer look at the no_overlap_with_range? method. The following illustration shows the cases in which we don’t even need to go further, we can already know that there won’t be any results.
There is no overlap under the four following conditions:
- the range spec min is greater than the max value:
set : |---|
range: |---| (min can be inclusive or exclusive, doesn't matter)
- the range spec min is exclusive and is equal to the max value:
set : |---|
range: (---| (min is exclusive)
- the min value is greater than range spec max:
set : |---|
range: |---| (max can be inclusive or exclusive, doesn't matter)
- the min value is equal to the range spec max which is exclusive:
set : |---|
range: |---( (max is exclusive)
In other words, if the range is to the right, or to the left of the set, with special cases around exclusivity, we don’t need to do any work, the result is empty.
One final word about no_overlap_with_range?, it calls the block with two arguments, the Pair instance itself, the first one in the set or the last one in the set, with their rank, which will allow us to use this method when dealing with range ranks, such as ZREMRANGEBYRANK for instance.
In practice the block.call expression will either return the score attribute, the member attribute or the rank value, for the pair. We could have written three methods, but the block based approach allows us to reuse the core logic for all three use cases.
Calling the block with two arguments might be an issue given that the block that was passed to the SortedSetSerializerBy constructor is &:score, what does passing multiple arguments to this block will do, let’s take a look at that now.
A note about blocks, arity and Ruby being weird
The need for the if block.arity != 2 line in the SortedSetSerializerBy constructor deserves its own section, because it’s kinda weird, Ruby does that sometimes. It’s easier to start with what would happen, without this block, we would always set @block to block, which is &:score at this moment, a block that is almost the equivalent of { |x| x.score }, with a big difference, how it handles its arguments.
Both versions create a Proc, and not a Lambda, there are two differences, lambdas return or break calls only affect the lambda itself, whereas returning from a Proc returns from the outer method. You can see that by running lambda { return 1 }.call in irb, and see that it returns 1. This is because we create a lambda, call it, and get back the return value of the lambda, 1. Now, run the proc version, proc { return 1 }.call, and you’ll get a LocalJumpError (unexpected return) exception back. This is because you can’t return in irb. You can see that by typing return on a new line and you’ll get the same error. This shows that calling return within the proc actually tried to return from the caller, the main irb session.
Blocks create procs and not lambdas, and this allows patterns such as returning early from the block, which is a pattern we use a lot in this chapter. Let’s look at an example using a block, a proc and a lambda:
def a_method(proc_or_lambda)
if block_given?
yield
else
proc_or_lambda.call
end
'reached the end of a_method'
end
def call_with_block
a_method(nil) { return 'nope' }
end
def call_with_lambda
a_method(lambda { return 'nope' })
end
def call_with_proc
a_method(proc { return 'nope' })
end
print "block: #{ call_with_block }\n"
print "lambda: #{ call_with_lambda }\n"
print "proc: #{ call_with_proc }\n"
Putting this in a file, say, proc_vs_block_vs_lambda.rb and running it with ruby proc_vs_block_vs_lambda.rb, we get the following result:
> ruby proc_vs_block_vs_lambda.rb
block: nope
lambda: reached the end of a_method
proc: nope
We only reached the end of a_method when using a lambda, because the return call only affected the lambda itself. This behavior is what allows us to do something like the following:
def first_item_or_nil(an_array)
an_array&.each { |element| return element }
end
This method might not seem really useful, we could have used [0] to return the first item, but it will return nil for a nil array whereas calling [0] on a nil value will raise a NoMethodError exception. Beside the small safety gain with this method, the point being that we can return from within the block, and that will affect the method where the block was created, in this case, head_or_nil. We’ll see a lot of actually useful cases later, such as in first_item_or_nil.
So blocks are procs, cool, now, the difference we care about here is how they handle different arguments being received:
irb(main):001:0> p = proc { |x| p x }
irb(main):002:0> p.call(1)
1
=> 1
irb(main):003:0> p.call(1, 2)
1
=> 1
irb(main):004:0> p = proc { |x, y| p x, y }
irb(main):005:0> p.call(1)
1
nil
=> [1, nil]
irb(main):006:0> p.call(1, 2)
1
2
=> [1, 2]
irb(main):007:0> l = lambda { |x| p x }
irb(main):008:0> l.call(1)
1
=> 1
irb(main):009:0> l.call(1, 2)
Traceback (most recent call last):
5: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `<main>'
4: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `load'
3: from /Users/pierre/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/irb-1.2.3/exe/irb:11:in `<top (required)>'
2: from (irb):10
1: from (irb):8:in `block in irb_binding'
ArgumentError (wrong number of arguments (given 2, expected 1))
irb(main):010:0> l = lambda { |x, y| p x, y }
irb(main):011:0> l.call(1)
Traceback (most recent call last):
5: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `<main>'
4: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `load'
3: from /Users/pierre/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/irb-1.2.3/exe/irb:11:in `<top (required)>'
2: from (irb):12
1: from (irb):11:in `block in irb_binding'
ArgumentError (wrong number of arguments (given 1, expected 2))
irb(main):012:0> l.call(1, 2)
1
2
=> [1, 2]
A Proc doesn’t really care, if it needs more arguments that you give it, it defaults to nil, if it receives too many arguments, it just ignores them. A lambda on the other hand is like a method, it requires the exact number of arguments. Things are a bit difference when arguments have default values and become optional, but let’s set that aside, it’s not really what our problem is. Note that it’s sometimes not explicit whether you’re dealing with a lambda or a proc, but you can always use the lambda? method when in doubt.
Now back to &:member, what it does is actually a bit unclear to me, because the block that is created is defined in some internal Ruby code, in C, but what we can do is inspect the block with some of the methods available on Proc, namely #parameters & #arity, let’s add this small snippet in a file called blocks.rb:
def inspect_ruby_block(&block)
puts "parameters: #{ block.parameters }"
puts "arity: #{ block.arity }"
puts "lambda?: #{ block.lambda? }"
end
inspect_ruby_block { |x| x.score }
p '---'
inspect_ruby_block(&:score)
Let’s run this with ruby blocks.rb:
parameters: [[:opt, :x]]
arity: 1
lambda?: false
"---"
parameters: [[:rest]]
arity: -1
lambda?: false
So neither are lambdas, cool, they should be handling arguments in a flexible way, but there’s a difference, their arity is not the same. Arity is just a fancy word for “how many arguments do they expect”. In the first example, the explicit block, the value is 1, which makes sense, we defined it as |x|, only one argument. But in the second example, it’s -1, which happens to be kinda similar to how Redis communicates arity for its commands. -1 means that it is variadic, it accepts a variable number of arguments, but what makes this even weirder is the result of the parameters call. The one argument does not have a name.
We can mimic a similar block with the following:
irb(main):002:0> inspect_ruby_block { |*| }
parameters: [[:rest]]
arity: -1
lambda?: false
=> nil
irb(main):003:0> inspect_ruby_block { |*a| }
parameters: [[:rest, :a]]
arity: -1
lambda?: false
=> nil
How Ruby goes from a block like that, that seems to accept a variable number of arguments without naming them and is able to return the score attribute, or whatever we passed after the semicolon in &: is unclear to me, but it leads us to the problem we’re trying to solve, this block, which is a proc, but of a slightly different kind, doesn’t behave the way we want if we pass too many arguments.
Let’s first create a method that returns the block it receives so that we can play with it. This is useful because the only way to create a block through the ampersand column approach is by passing it as an argument, so by returning it, we’ll get a hold of the block in a variable:
def capture_block(&b)
b
end
And now let’s look at the differences in behavior:
irb(main):018:0> block = capture_block { |*| }
irb(main):019:0> block.call(1)
=> nil
irb(main):020:0> block.call(1, 2)
=> nil
So far, this is what we would expect, the block does nothing, and it silently accepts any number of arguments, but now let’s take a look at the &:score approach:
irb(main):025:0> block = capture_block(&:score)
irb(main):026:0> block.call(Struct.new(:score).new(12))
=> 12
If we want to call block, we need an object that has a score method, so in one line we create a Struct, and instantiate it, and it works, so far so good. Now let’s see what happens if we pass a second argument, which is what we want to do, call a block with a Pair and a number representing its rank:
irb(main):027:0> block.call(Struct.new(:score).new(12), 10)
Traceback (most recent call last):
5: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `<main>'
4: from /Users/pierre/.rbenv/versions/2.7.1/bin/irb:23:in `load'
3: from /Users/pierre/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/irb-1.2.3/exe/irb:11:in `<top (required)>'
2: from (irb):27
1: from (irb):27:in `score'
ArgumentError (wrong number of arguments (given 1, expected 0))
Yup, it blows up, and honestly, I can’t really tell you why. My guess? By being defined in C, it is able to use the low level APIs of the language, and can say “give me the first argument, and call the method named after the argument I was created with on it”. It’s also interesting to look specifically at the error we get.
It gives us a hint, wrong number of arguments (given 1, expected 0), for score, so it seems like it tried to pass 10, the second argument to score, which is a getter and only takes a single argument, so the &: approach can apparently be used for methods that require arguments, let’s confirm this by creating this class in irb:
class A
def a_variadic_method(*args)
p args
end
end
The method a_variadic_method is variadic, it accepts any number of arguments, and it prints them, let’s now use this with a block created with the &: approach:
irb(main):012:0> b = capture_block(&:a_variadic_method)
irb(main):013:0> b.call(A.new)
[]
=> []
irb(main):014:0> b.call(A.new, 1, 2, 3)
[1, 2, 3]
=> [1, 2, 3]
We capture a block that will call a_variadic_method on its argument and first call it with an instance of A, and get back an empty array, it’s because no arguments were given to a_variadic_method, so args was set to []. Now let’s add arguments to the block.call line, and we see that we get them back as an array, because they were passed as arguments! So what did we learn here, that a block created with &: is variadic and requires at least one argument, to call the method it was created with on, and if it receives any other arguments, it will pass them as arguments to the method.
So anyway, what can we do? Well, we can create a block that accepts the number of arguments we need it to receive if we know it otherwise wouldn’t be able to handle them. Reusing the same block variable from the previous example defined as block = capture_block(&:score):
irb(main):031:0> wrapper_block = proc { |pair, rank| block.call(pair) }
irb(main):032:0> wrapper_block.call(Struct.new(:score).new(12), 10)
=> 12
irb(main):033:0> wrapper_block.call(Struct.new(:score).new(12))
=> 12
The second argument of the block is ignored, and we can pass a single argument! Just what we wanted!
It’s worth noting that we could have also changed the behavior when creating a SortedSetSerializerBy, with:
SortedSetSerializerBy.new(sorted_set, range_spec, **options) { |x, _| x.score }
But I do believe that it is convenient to be able to only pass a single argument, since that’s really what this block is saying: “This block, which is used to extract a variable from a Pair returns its score”. It would be a little bit annoying to have to worry about a second argument, and ignoring it.
Serializing a ZSet
The two methods dedicated to serializing the ZSet or the List are pretty long, because they’re written in a generic way that will allow them to be reused for the *REV* commands and the *LEX* commands. Let’s start with serialize_zset, once again ignoring the @reverse flag for now, and assuming it to always be false.
We start by creating the members array, which will hold all the values we need to serialize for the final result.
We then find the index of the first item that fits in the range with the SortedArray#first_index_in_range method, and use it to create the indices enumeration, which contain all the indices we want to inspect. This step is a way to skip all the elements to left of the the first element that fits in the range by directly “jumping” to the first item in the range. This approach is a big win for a large set, where for instance, jumping to an element in the middle of the array would require way less steps that iterating one by one from the beginning of the array.
We then iterate through the indices and inspect each Pair we find. Using the in_range? method, we can determine whether or not the current element is in the range. Note that we use the block variable, which was set to &:score. As discussed earlier, this notation is a shortcut for { |x| x.score }. This approach makes the SortedSetSerializerBy agnostic of which fields we’re serializing by, the caller gets to decide by passing the right block.
The in_range? method will always return true for the first element, because first_index_in_range pointed us as the first element in range, but as we keep iterating to the right in the array, we might end up encountering an element that is outside the range, in which case we want to stop iterating.
We also need to handle the COUNT and OFFSET options. Because of the OFFSET option, we might need to ignore the first items we find, so if the current item is in the range, we decrement @offset until it reaches 0. If its value is 0 or less, then we start accumulating elements in members, with or without their score, depending on the WITHSCORES option. For each element we accumulate, we decrement @count, and break once it reaches 0, telling us we’ve accumulated enough elements. This logic relies on the fact that we use a default value of -1 for @count, meaning that by default we’ll keep decrementing, and it will have no effect since its value will never reach 0.
As a quick note, the last sentence is true in Ruby, an integer that is initialized at -1 cannot possibily reach 0 if we keep decrementing, but it is false in a language where integers can overflow, like C! We’ve already spent a lot of time talking about integers in the previous chapter, so we’ll only say that once a signed integer reaches the minimul value its encoding allows, subtracting 1 will become the maximum of the range, and we keep subtracting, we’ll reach 0 again. The following program outputs: reached 0 (proof: 0) in 65535 steps:
#include <stdio.h>
int main(void) {
short i = -1;
int steps = 0;
while (i != 0) {
i--;
steps++;
}
printf("reached 0 (proof: %i) in %i steps", i, steps);
return 0;
}
listing 10.25 A C example of integer overflow and the wrapping behavior
Let’s add the first_index_in_range method to SortedArray:
module BYORedis
class SortedArray
# ...
def first_index_in_range(range_spec)
return nil if empty?
@underlying.bsearch_index do |existing_element|
compare = range_spec.compare_with_min(yield(existing_element))
if range_spec.min_exclusive?
compare > 0 # existing_element.score > min
else
compare >= 0 # existing_element.score >= min
end
end
end
end
end
listing 10.26 The SortedArray#first_index_in_range method
This method is a generic approach to using the following block:
array.bsearch_index do |pair|
pair.score >= range_spec.min # or pair.score > range_spec.min if exclusive
end
Using the block approach will allow us to use the same method, but with the member value instead, in the lex command below, and using the compare_with_min method handles the specifities of the comparison logic. Things are not too complicated for now, we’re comparing two float values with a <=> b, but will become a bit trickier in the lex case with the + & - special values, just a heads-up!
Note that the block we’re dealing with here is, in this case, the one passed to the constructor of SortedSetSerializerBy, but after being wrapped in a proc ignoring its second argument, so calling yield with a single argument will not cause any issues.
The use of the comparison instead of directly using the > or < operator adds an extra level of indirection that can make things a little bit confusing, that being said, it does allow for a greater level of reusability, so its readability cost comes with some benefit. Let’s look at an example to see what the first_index_in_range really does:
irb(main):001:0> require_relative './sorted_array'
=> true
irb(main):002:0> require_relative './redis_sorted_set'
=> true
irb(main):003:0> array = BYORedis::SortedArray.by_fields(:score, :member)
irb(main):004:0> array << BYORedis::RedisSortedSet::Pair.new(1, 'a')
=> [#<struct BYORedis::RedisSortedSet::Pair score=1, member="a">]
irb(main):005:0> array << BYORedis::RedisSortedSet::Pair.new(2, 'b')
=> [#<struct BYORedis::RedisSortedSet::Pair score=1, member="a">, ...]
irb(main):006:0> array << BYORedis::RedisSortedSet::Pair.new(3, 'c')
=> [#<struct BYORedis::RedisSortedSet::Pair score=1, member="a">, ...]
irb(main):007:0> array << BYORedis::RedisSortedSet::Pair.new(4, 'd')
=> [#<struct BYORedis::RedisSortedSet::Pair score=1, member="a">, ...]
irb(main):008:0> array << BYORedis::RedisSortedSet::Pair.new(26, 'z')
=> [#<struct BYORedis::RedisSortedSet::Pair score=1, member="a">, ...]
irb(main):009:0> range_spec = BYORedis::RedisSortedSet::GenericRangeSpec.score_range_spec(2, 4, false, false)
irb(main):010:0> array.first_index_in_range(range_spec) { |x| x.score }
=> 1
This example shows that, at least in this one example, it worked, 1 is indeed the first element of the array that is in the range 2 4. The other indices of members in the range are 2 and 3. The trick relies once again on bsearch_index, which can be a really powerful once you get the hang of it. In this example we rely on its find-minimum mode. In this mode we need to give it a block that returns the following values according to the documentation:
In find-minimum mode (this is a good choice for typical use cases), the block must always return true or false, and there must be an index i (0 <= i <= ary.size) so that:
- the block returns false for any element whose index is less than i, and
- the block returns true for any element whose index is greater than or equal to i.
In other words, the method will return the smallest index, which can also be seen as the leftmost index, for which the block is true. Or, alternatively phrased, the index after the greatest index for which the block is false.
Equipped with this definition, we can use it to find the first element that fits in the range, with the block { |x| x > min }, the block will be false if it finds an element in the array equal to the min value of the range, and it will therefore return the index of the element after that, which is the first element of the range if the exclusive flag is set for the min value. Looking at it from the other angle, the block will be true for all values greater than min, and false for all values lower than min, including min itself.
The block { |x| x >= min } will return true as long the element being inspected by bsearch_index is greater or equal than the minimum value, so it if finds an element in the array equal to the min, it will return that index, otherwise, it will return the index of the smallest value that is still greater than the min. That’s the index of the first element in the range if min is not exclusive
Now let’s look at the convoluted way in which first_index_in_range ends up achieving exactly what we described. As mentioned earlier, in order to keep the method abstract, we refuse to call existing_element.score directly, and instead delegate to the caller to decide what attribute to use, which is what yield(existing_element) does. In this example, the block given is @block, in the line @sorted_set.underlying.array.first_index_in_range(@range_spec, &@block), with the ampersand to tell Ruby it’s not just a regular argument, it’s a block. @block is the value of the block given to the constructor, which was done in the SortedSetUtils.generic_range_by_score method and is &:score, the equivalent of { |x| x.score }. We use the value returned by yield, and feed it to compare_with_min, which calls score <=> min.
The value returned by compare_with_min will be 1 if existing_element.score > range_spec.min, 0 if they’re equal and -1 if existing_element.score < range_spec.min.
So now we can look at what we return from the block in first_index_in_range, in the min_exclusive? case we return compare > 0, which is the same as returning existing_element.score > range_spec.min, and in the non exclusive case, compare >= 0 is the equivalent of existing_element.score >= range_spec.min, these are the values that will lead bsearch_index to return the index of the first element in the range, min being exclusive or not.
Why are we jumping through all these hoops? Well, it’ll make writing the next similar commands a breeze!
Serializing a List
We’ve looked at the serialize_zset private method in SortedSetSerializerBy, let’s now look at serialize_list. Once again, let’s set the @reverse branches aside and assume it always holds its default value for now, false.
We start by creating a left to right iterator, since we have no way to know where the first element in the range is in the list, we’ll start from the left and iterate from there.
Similarly to the ZSet case, we create an array, members, which we’ll use to aggregate the values as we find them, we also create a boolean that will help us exiting the loop early and prevent to unnecessarily iterate through the whole list if we can avoid it.
We start iterating with the iterator, as well as with the while condition @count != 0. This is the same optimization as earlier, if a count was specified, then we’ll stop iterating once we’ve accumulated enough elements, but if no count value is given, then the value will start at -1 and decrement from there, and this condition will never trigger.
For each element in the look, we ask the range if it is in the range, with @range_spec.in_range?(@block.call(member)). If this returns true, we first flag entered_range to true, which we only do once, there’s no need to set the value again once we’ve done it. Next, we take the @offset value into account, the same way we did in the ZSet case, and if we’ve skipped enough values as indicated by @offset, then we start accumulating values, with or without scores, depending on the @withscores option. We always decrement the count value, to make sure that the while condition we just mentioned stops the loop once we’ve accumulated enough elements.
If the element is not in the range, then we also check if we have previously entered the range, and if we did, then it means that we just found the first element that is outside the range. This tells us that we’ve found the last element that could be in the range, there’s no point in continuing from now on and we exit the loop.
If we have not exited the loop early, then we keep going through the list. Once the whole iteration is done, we return the serialized members array.
By Lexicographic Order
Let’s add the last ZRANGE* command, ZRANGEBYLEX, but before looking at the ZRangeByLexCommand class, we need to spend some time looking at what a “lex range” is.
First things first, the same way numbers can be sorted, strings can be sorted. Well, technically, as we’ve seen before, string are really array of bytes under the hood, and bytes are numbers, kinda. At least bytes have a numeric value, that’s the accurate way of describing it. 'a' is 97, 'b' is 98, etc … but that’s an implementation detail! We can look at a dictionary to see a real life example. A come before B, and so on, and if there is a tie, we compare the next letter, and the next, and if there’s still a tie, the shorter string is always the shortest one, that makes 'aa' < 'aaa' a true comparison. Lower case letters are considered greater than their upper case equivalent, the following is true, 'A' < 'a'. And for reference, 'A'.ord == 65, 65 is indeed lower than 97.
At its core, that’s what a lex range is, instead of using numbers like we’ve done before, such as 0 2, or 0 -1, a lex range is expressed as a z, or aa aaa. And the same way that 2 0 was nonsensical when used to return the range in a list, something like d a is nonsensical as well, these are empty ranges, there cannot be any elements that fits in them.
There are two more things we need to cover about lex ranges, exclusivity with [ & ( and special values with - & +.
Let’s start with the bracket and parenthesis first. Range boundaries need to be explicitly marked as inclusive or exclusive, [ means inclusive, and ( means exclusive. Note that these characters are mandatory. Let’s look at few examples:
127.0.0.1:6379> ZADD z 0 a 0 b 0 c 0 d
(integer) 4
127.0.0.1:6379> ZRANGEBYLEX z (a (d
1) "b"
2) "c"
127.0.0.1:6379> ZRANGEBYLEX z [a (d
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> ZRANGEBYLEX z [d [a
(empty array)
127.0.0.1:6379> ZRANGEBYLEX z [aa (d
1) "b"
2) "c"
127.0.0.1:6379> ZRANGEBYLEX z [d [z
1) "d"
127.0.0.1:6379> ZRANGEBYLEX z (d [z
(empty array)
The set z contains the four members a, b, c & d. The first ZRANGEBYLEX calls is requesting all the elements between a and d, excluding both of them, and it returns b & c. The second example marks a as inclusive and the results includes it. The following example shows an instance of an empty range, d is greater than a, so that range does not make any sense. The next example shows how the string 'aa' is considered greater than 'a' which explains why 'a' is not returned.
In the second to last example d is marked as inclusive and is the only element returned, in the last example d is marked as exclusive and is not returned.
Finally, - and + play a role similar to -inf and +inf in the ZRANGEBYSCORE method, they can be used to specify respectively a value this lower than any other values, and a value that is greater than any other values. A different with the infinity values is what while a score can have the value -inf or inf, no strings can actually have this special value. You could set a member with the value - or +, but that’s not the same, these are the characters + and -. You could request them with: ZRANGEBYLEX z [+ [- but that’s different from requesting ZRANGEBYLEX z - +. As a quick aside, - is greater than +, they have the values 43 & 45. The character '*' has the value 42, so we could use it:
127.0.0.1:6379> ZADD z 0 +
(integer) 1
127.0.0.1:6379> ZADD z 0 -
(integer) 1
127.0.0.1:6379> ZRANGEBYLEX z - +
1) "+"
2) "-"
127.0.0.1:6379> zrangebylex z [+ [-
1) "+"
2) "-"
127.0.0.1:6379> zrangebylex z [* [-
1) "+"
2) "-"
I’m not sure if you’d ever want to use these values in a range, because that is pretty cryptic, but it is important to understand how these ranges work.
The ZRANGEBYLEX command has the following format according to the Redis documentation:
ZRANGEBYLEX key min max [LIMIT offset count]
module BYORedis
module SortedSetUtils
# ...
def self.generic_range_by_lex(db, args, reverse: false)
# A negative count means "all of them"
options = { offset: 0, count: -1 }
Utils.assert_args_length_greater_than(2, args)
key = args.shift
if reverse
max = args.shift
min = args.shift
else
min = args.shift
max = args.shift
end
range_spec = Utils.validate_lex_range_spec(min, max)
parse_range_by_lex_options(args, options) unless args.empty?
sorted_set = db.lookup_sorted_set(key)
if options[:offset] < 0
EmptyArrayInstance
elsif sorted_set
options[:withscores] = false
options[:reverse] = reverse
SortedSetSerializerBy.new(sorted_set, range_spec, **options, &:member)
else
EmptyArrayInstance
end
end
def self.parse_range_by_lex_options(args, options)
raise RESPSyntaxError unless args.length == 3
if args.shift.downcase == 'limit'
SortedSetUtils.parse_limit_option(args, options)
else
raise RESPSyntaxError
end
end
end
# ...
class ZRangeByLexCommand < BaseCommand
def call
SortedSetUtils.generic_range_by_lex(@db, @args, reverse: false)
end
def self.describe
Describe.new('zrangebylex', -4, [ 'readonly' ], 1, 1, 1,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.27 The ZRangeByLexCommand class
The generic_range_by_lex method will be useful when we add the reverse variant, ZREVRANGEBYLEX, which is why it has a reverse flag, which defaults to false. We need to validate that min and max are valid lex range items, and if they are, we create an instance of the range spec class specific to lexicographic order, with GenericRangeSpec.lex_range_spec:
module BYORedis
module Utils
# ...
def self.validate_lex_range_spec(min, max)
min_string, min_exclusive = parse_range_item(min)
max_string, max_exclusive = parse_range_item(max)
RedisSortedSet::GenericRangeSpec.lex_range_spec(
min_string, max_string, min_exclusive, max_exclusive)
end
def self.parse_range_item(item)
if item == '+'
[ '+', true ]
elsif item == '-'
[ '-', true ]
elsif item[0] == '['
[ item[1..-1], false ]
elsif item[0] == '('
[ item[1..-1], true ]
else
raise ValidationError, 'ERR min or max not valid string range item'
end
end
private_class_method :parse_range_item
end
listing 10.28 The Utils.validate_lex_range_spec class
validate_lex_range_spec checks the format of both range items with parse_range_item. In this method we check all the edge cases. + and - are considered exclusive since no values can actually be equal to them. Let’s now create a new class method on GenericRangeSpec to create a range spec that uses lex comparison as its ordering mechanism:
module BYORedis
class RedisSortedSet
# ...
class GenericRangeSpec
# ...
def self.lex_range_spec(min, max, min_exclusive, max_exclusive)
GenericRangeSpec.new(min, max, min_exclusive, max_exclusive) do |a, b|
RedisSortedSet.lex_compare(a, b)
end
end
# ...
end
# ...
def self.lex_compare(s1, s2)
return 0 if s1 == s2
return -1 if s1 == '-' || s2 == '+'
return 1 if s1 == '+' || s2 == '-'
s1 <=> s2
end
# ...
end
# ...
end
listing 10.29 The GenericRangeSpec.lex_range_spec class method
The comparison of lex items is a bit trickier than previous comparisons we’ve had to deal with previously and is why we previously created the compare_with_min and compare_with_max methods. It is implemented in the lex_compare and essentially follows these rules:
- If both strings are equal, return
0 - Otherwise, if the first string is
-, or if the second string is+, then the first string is smaller than the second one - Otherwise, if the first string is
+or the second string is-, then the first string is greater than the second string. - Otherwise, compare the strings the “regular” way, with
<=>, that isbis greater thanaa, which is greater thana, etc … This is theString#<=>method.
By using this new comparison system, but still returning -1, 0, and 1 depending on the order, we can reuse all the code from GenericRangeSpec, neat!.
And now that we’ve looked at this new way of using GenericRangeSpec, let’s look at all the pieces falling into place.
Back in SortedSetUtils.generic_range_by_lex, we now call SortedSetSerializerBy with the sorted set, the range spec, the parsed options, namely LIMIT and OFFSET, and the block &:member, the equivalent of { |x| x.member }.
We’ve spent a good amount of time talking about why we wrote SortedSetSerializerBy in a way that never explicitly called .score or .member, or even knew how to compare elements, and this is about to pay off.
The serialize method in SortedSetSerializerBy can now return early if the range spec is empty, and the range spec is now a GenericRangeSpec created with RedisSortedSet.lex_compare(a, b) as the comparison block, so it will know how to compare the min and max elements and determine if the lex range is empty. It will also call no_overlap_with_range? with the block we gave it, which extracts the member attribute from a pair, and will again return early, if it determines that there is no overlap between ranges.
Both specific methods, serialize_zset and serialize_list, function the exact same way as we explored in ZRANGEBYSCORE, the range spec says whether or not an item is in range, and if so they’re accumulated, with or without their scores, in an array and returned to the user.
And we’ll be able to reuse a lot of this code soon with the *REV* commands too!
Set Operations, Union & Intersection
Sorted sets support set operation commands similar to the ones we added in the previous chapter, the SINTER and SUNION methods in the previous chapters, as well as their *STORE variants.
As of Redis 6.0 there is no ZDIFF and ZDIFFSTORE commands, but it might be added soon as there is an active Pull Request as of November 2020: https://github.com/redis/redis/pull/7961. It should be added in 6.2.0.
The topic of the ZDIFF command has been discussed for a while, an earlier PR dates from April 2012: https://github.com/redis/redis/pull/448
The initial resistance to adding a ZDIFF commands has been discussed in the mailing list and can be summarized by this 2010 comment from Redis developer Pieter Noordhuis:
ZDIFFSTORE makes no sense, as discussed before on the ML (please search before posting). The intrinsic value of the scores gets lost when you simply start subtracting them
As we’re about to see, both ZINTER and ZUNION offer mechanisms to let users decide what happens to the score values from multiple sets and how to combine them. On the other hand, things would be different with ZDIFF as values could be completely discarded.
Set Intersection
Let’s look at ZINTER first. Note that ZINTER was only added in Redis 6.2.0, in earlier versions only ZINTERSTORE was available.
127.0.0.1:6379> ZADD z1 0 a 1 b 2 c
(integer) 3
127.0.0.1:6379> ZADD z2 10 z 5 x 3 c
(integer) 3
127.0.0.1:6379> ZINTER 2 z1 z2
1) "c"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES
1) "c"
2) "5"
ZINTER requires the first argument to be the number of sets that will be given next. Without this explicit count argument, the command ZINTER z1 z2 WITHSCORES would be ambiguous, what if there is a set at the key WITHSCORES, did you mean the intersection of the three sets z1, z2 & WITHSCORES, or the intersection of z1 and z2 with the option WITHSCORES?
The numkeys argument prevents this and makes the number of set explicit.
We can see in the previous example that the score of the only element in the result set is 5, which is the sum of the score for member c in z1 and the score for member c in z2. The aggregation of scores default to SUM and can be controller with the AGGREGATE option. The other two possible values are MIN and MAX:
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES AGGREGATE MAX
1) "c"
2) "3"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES AGGREGATE MIN
1) "c"
2) "2"
The last option to ZINTER is WEIGHTS, it must be followed by a list of valid float values, of length equal to numkeys. In other words, if you explicit pass the WEIGHTS option, you need to give a weight for each set we’re computing the intersection of. The implicit default value of the weights is 1. When combining values in the final set, each score will be multiplied by the weight given to its set:
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 1 1
1) "c"
2) "5"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 1 2
1) "c"
2) "8"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 1 3
1) "c"
2) "11"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 10 3.2
1) "c"
2) "29.600000000000001"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 10 inf
1) "c"
2) "inf"
As we can see, WEIGHTS 1 1 returns the same as if we had omitted the weights, 5. With WEIGHTS 1 2, all the members from the second set, z2 will have their weight multiplied by 2 before being aggregated, so 2 * 1 + 3 * 2 == 8, and in the next example we end up at 11 with 2 * 1 + 3 * 3.
The next example show that weights can be float, so 2 * 10 + 3 * 3.2 ~= 29.6.
In the last example, we end up with inf because any values multiplied by infinity equals infinity.
The weight values are applied before the aggregation:
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 100 10 AGGREGATE MAX
1) "c"
2) "200"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 100 10 AGGREGATE MIN
1) "c"
2) "30"
127.0.0.1:6379> ZINTER 2 z1 z2 WITHSCORES WEIGHTS 100 10 AGGREGATE SUM
1) "c"
2) "230"
200 is the result of MAX((2 * 100), (3 * 10)), 30 is the result of MIN((2 * 100), (3 * 10)) and 230 is the result of SUM((2 * 100), (3 * 10)).
Finally, ZINTER accepts regular sets, and assumes a score of 1 for each score-less set members.
127.0.0.1:6379> ZINTER 3 z1 z2 s WITHSCORES
1) "c"
2) "6"
127.0.0.1:6379> ZINTER 3 z1 z2 s WITHSCORES WEIGHTS 0 0 1
1) "c"
2) "1"
Let’s now create the ZInterCommand class, but first, since we already know we have three more very similar commands coming up soon, ZINTERSTORE, ZUNION & ZUNIONSTORE, let’s go ahead and add methods in SortedSetUtils in order to reuse code across these commands.
The Redis documentation describes the format of the command as:
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
module BYORedis
module SortedSetUtils
# ...
def self.intersection(db, args)
set_operation(db, args) do |sets_with_weight, aggregate|
RedisSortedSet.intersection(sets_with_weight, aggregate: aggregate)
end
end
def self.set_operation(db, args)
options = { aggregate: :sum, withscores: false }
sets = SortedSetUtils.validate_number_of_sets(db, args)
options.merge!(SortedSetUtils.parse_union_or_inter_options(args, sets.size))
sets_with_weight = sets.zip(options[:weights])
new_set = yield sets_with_weight, options[:aggregate]
return new_set, options[:withscores]
end
def self.set_operation_command(args)
Utils.assert_args_length_greater_than(1, args)
set_result, withscores = yield
SortedSetRankSerializer.new(
set_result,
RedisSortedSet::GenericRangeSpec.rank_range_spec(0, -1, set_result.cardinality),
withscores: withscores,
)
end
def self.parse_union_or_inter_options(args, number_of_sets)
options = { weights: Array.new(number_of_sets, 1) }
while arg = args.shift
case arg.downcase
when 'weights'
options[:weights] = validate_weights(number_of_sets, args)
when 'aggregate'
aggregate_mode = args.shift
case aggregate_mode&.downcase
when 'min' then options[:aggregate] = :min
when 'max' then options[:aggregate] = :max
when 'sum' then options[:aggregate] = :sum
else raise RESPSyntaxError
end
when 'withscores' then options[:withscores] = true
else raise RESPSyntaxError
end
end
options
end
def self.validate_number_of_sets(db, args)
number_of_sets = Utils.validate_integer(args.shift)
if number_of_sets <= 0
raise ValidationError, 'ERR at least 1 input key is needed for ZUNIONSTORE/ZINTERSTORE'
else
number_of_sets.times.map do
set_key = args.shift
raise RESPSyntaxError if set_key.nil?
db.lookup_sorted_set_or_set(set_key)
end
end
end
def self.validate_weights(number_of_sets, args)
number_of_sets.times.map do
weight = args.shift
raise RESPSyntaxError if weight.nil?
Utils.validate_float(weight, 'ERR weight value is not a float')
end
end
end
# ...
class ZInterCommand < BaseCommand
def call
SortedSetUtils.set_operation_command(@args) do
SortedSetUtils.intersection(@db, @args)
end
end
def self.describe
Describe.new('zinter', -3, [ 'readonly', 'movablekeys' ], 0, 0, 0,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.30 The ZInterCommand class
The ZInterCommand is surprisingly short, it essentially amounts to the two statements: “Perform a regular set operation, no store, and use the intersection operation”. Using this level of abstraction will allow us to write the following commands in a very concise way as well, but let’s look at what SortedSetUtils.set_operation_command and SortedSetUtils.intersection do.
set_operation_command is the method that performs the first validation, we need at least two arguments, the number of sets, numkeys and at least one set key. It then uses yield to give back the values of the actual result, as well as the options to the caller, the call method. The results from yield, which we’ll look at shortly, are then fed to the SortedSetRankSerializer class, the same class we used to implement the ZRANGE command. With the range from 0 to -1 this serializer will serialize the whole set, in rank order, which is what we need to return. The value of withscores, as well as set_result, come from calling yield, which returns SortedSetUtils.intersection(@db, @args) as we can see in the ZInterCommand class. This intersection method is a wrapper around RedisSortedSet.intersection, with a few additional steps, such as parsing all the remaining options, WEIGHT, AGGREGATE and WITHSCORES.
These steps are performed in the SortedSetUtils.set_operation, which first calls the methods validate_number_of_sets, to check that we have the correct number of keys after the numkeys argument, and loads all the set with DB#lookup_sorted_set_or_set.
We need this new method because this commands and the other set union commands for sorted sets accept regular sets as arguments as well:
module BYORedis
class DB
# ...
def lookup_sorted_set_or_set(key)
set = @data_store[key]
raise WrongTypeError if set && !set.is_a?(RedisSortedSet) && !set.is_a?(RedisSet)
set
end
end
end
listing 10.31 The DB#lookup_sorted_set_or_set method
Going back to set_operation, the next step is calling parse_union_or_inter_options. At this time we’ve parsed the value of numkeys so we know how many sets to expect, which means that if the WEIGHTS option is present, we have to validate that the number of weights matches the numkeys value. This validation is performed in the validate_weights method. We generate the default weight values with the line Array.new(number_of_sets, 1). It initializes an array for which the size is number_of_sets, and all the elements are 1.
The other options we need to check for are aggregate, in which case the next argument must be one of min, max, or sum, and withscores, if it is present, we set the corresponding flag to true.
The parse_union_or_inter_options is a little bit simpler than the parse_options method in the ZAddCommand class because the options come at the end of the argument list here. This allows us to skip the whole “peek and only consume if the head is an option” approach we used there. Here we can shift as long as we find valid options.
The Array#zip method
Once the weight values have been parsed into BigDecimal instances, we combine them with the set objects with the Array#zip method. This is a method we haven’t used so far so let’s take a quick look at what it does, sure, it “zips” things, but what does it mean?
irb(main):001:0> a1 = [1,2,3,4]
irb(main):002:0> a2 = ['a','b','c','d']
irb(main):003:0> a1.zip(a2)
=> [[1, "a"], [2, "b"], [3, "c"], [4, "d"]]
zip is called on an array and the arguments are one or more arrays, the result is … also an array, where each element is … another array, which is the combination of elements from all the arrays at matching indices! Yup, that’s a lot of arrays.
Let’s look at what happens with three arrays:
irb(main):004:0> a3 = [true, false, true, false]
irb(main):005:0> a1.zip(a2, a3)
=> [[1, "a", true], [2, "b", false], [3, "c", true], [4, "d", false]]
We can even reuse zip an array with itself:
irb(main):006:0> a1.zip(a2, a3, a1)
=> [[1, "a", true, 1], [2, "b", false, 2], [3, "c", true, 3], [4, "d", false, 4]]
Lastly, let’s look at the behavior when the lengths don’t exactly match:
irb(main):007:0> a1.zip([ true ])
=> [[1, true], [2, nil], [3, nil], [4, nil]]
irb(main):008:0> [true].zip(a1)
=> [[true, 1]]
The final result is always the same length as the Array we called zip on, and nil values are thrown in there if the other arrays are too small.
Finalizing the set intersection operation
Back to the our use of the zip method in set_operation, we have an Array of RedisSortedSet or RedisSet and an Array of BigDecimal, and we zip them together in an array of pairs. This will allow us to iterate over the pairs and each element will contain a set, either sorted or not, and its weight.
The next line in set_operation is new_set = yield sets_with_weight, options[:aggregate], where we delegate the work of actually performing the operation, union, or intersection to the caller, in our case, the block SortedSetUtils.intersection method, which calls RedisSortedSet.intersection, with the sets, weights and options that set_operation took care of parsing for us.
Once the set operation is performed, the whole stack unravels and the set_operation_command ends up back in control, it finally has a value for set_result, and feeds it to SortedSetRankSerializer, which is returned by ZInterCommand#call.
That was a lot of blocks, yields, method calls, so let’s summarize it:
ZInterCommand#callcallsSortedSetUtils.set_operation_commandwith a blockSortedSetUtils.set_operation_commandvalidates the length of the argument list and yields back toZInterCommand#callZInterCommand#callcallsSortedSetUtils.intersectionfrom the block now that the argument list is confirmed to have the required number of elementsSortedSetUtils.intersectioncallsSortedSetUtils.set_operationwith a blockSortedSetUtils.set_operationdoes a lot of the heavy lifting, loading the sets from memory, failing if they’re of the wrong type, parsing all the arguments, and yields all that back toSortedSetUtils.intersectionwith thesets_with_weightsandaggregatevariable.SortedSetUtils.intersectioncallsRedisSortedSet.intersectionfrom the block with thesets_with_weightandaggregatevariables- The result of
RedisSortedSet.intersectionis handled bySortedSetUtils.set_operationwith the linenew_set = yield sets_with_weight, options[:aggregate], and it then returns it, alongside thewithscoresoption. - The result of
SortedSetUtils.set_operationis handled bySortedSetUtils.set_operation_commandwith theset_result, withscores = yieldline, which it uses to create an instance ofSortedSetRankSerializer. - The result of
SortedSetUtils.set_operation_commandis the last line ofZInterCommand#calland is what is returned to theServerclass.
The following is a summary of the main methods called:
call { Utils.intersection }
set_operation_command
validations
Utils.intersection (through yield)
set_operation { RedisSortedSet.intersection }
validations
RedisSortedSet.intersection (through yield)
SortedSetRankSerializer.new
And with that, the ZINTER commands is done.
Well, almost, we haven’t looked at the actual intersection implementation, in RedisSortedSet, let’s do that now:
module BYORedis
class RedisSortedSet
# ...
def self.intersection(sets_with_weight, aggregate: :sum)
# Sort the sets smallest to largest
sets_with_weight.sort_by! { |set, _| set.nil? ? 0 : set.cardinality }
smallest_set = sets_with_weight[0][0]
smallest_set_weight = sets_with_weight[0][1]
return RedisSortedSet.new if smallest_set.nil?
intersection_set = RedisSortedSet.new
# Iterate over the first set, if we find a set that does not contain the member, discard
smallest_set.each do |set_member|
present_in_all_other_sets = true
if set_member.is_a?(Pair)
pair = set_member
else
pair = Pair.new(BigDecimal(1), set_member)
end
weighted_pair_score = Utils.multiply_or_zero_if_nan(smallest_set_weight, pair.score)
# For each member of the smallest set, we loop through all the other sets and try to
# find the member, if we don't find it, we break the loop and move on, if we do find
# a member, then we need to apply the weight/aggregate logic to it
sets_with_weight[1..-1].each do |set_with_weight|
set = set_with_weight[0]
weight = set_with_weight[1]
if set == smallest_set
other_pair = pair
elsif set.is_a?(RedisSet)
other_pair = set.member?(pair.member) ? Pair.new(BigDecimal(1), pair.member) : nil
elsif set.is_a?(RedisSortedSet)
other_pair = set.find_pair(pair.member)
else
raise "Unknown set type: #{ set }"
end
if other_pair
weighted_other_pair_score = Utils.multiply_or_zero_if_nan(other_pair.score, weight)
weighted_pair_score =
case aggregate
when :sum then weighted_pair_score + weighted_other_pair_score
when :max then [ weighted_other_pair_score, weighted_pair_score ].max
when :min then [ weighted_other_pair_score, weighted_pair_score ].min
else raise "Unknown aggregate method: #{ aggregate }"
end
else
present_in_all_other_sets = false
break
end
end
# Otherwise, keep
if present_in_all_other_sets
intersection_set.add(weighted_pair_score, pair.member, {})
end
end
intersection_set
end
def self.aggregate_scores(aggregate, a, b)
case aggregate
when :sum then Utils.add_or_zero_if_nan(a, b)
when :max then a < b ? b : a
when :min then a < b ? a : b
else raise "Unknown aggregate method: #{ aggregate }"
end
end
private_class_method :aggregate_scores
# ...
def find_pair(member)
case @underlying
when List then list_find_pair(member)
when ZSet
dict_entry = @underlying.dict.get_entry(member)
Pair.new(dict_entry.value, dict_entry.key) if dict_entry
else raise "Unknown type for #{ @underlying }"
end
end
def empty?
cardinality == 0
end
def each(&block)
case @underlying
when List then @underlying.each(&block)
when ZSet then @underlying.array.each(&block)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def list_find_pair(member)
@underlying.each do |pair|
return pair if pair.member == member
end
nil
end
end
end
listing 10.32 The RedisSortedSet.intersection method
The logic is overall similar to the one we wrote in RedisSet.intersection, with the main difference being that we need to handle weights, and how to aggregate them. We start in a similar way, we sort sets from smallest to largest, because that way we will only iterate through the smallest set. If that set is nil, then we don’t even have to go further, an empty set in an intersection guarantees that the result is an empty set. Like 0 in a multiplication, it doesn’t matter what the other parts of the operation are.
Once sets are sorted, the smallest set is the value at sets_with_weight[0][0], the first element in the first pair of the main array, and its weight is at sets_with_weight[0][1], the second element in the first pair of the main array. Remember that sets_with_weights looks like the following where 's1', 's2' & 's3' are set instances:
[
[ 's1', 1 ],
[ 's2', 10 ],
[ 's3', 0.5 ],
]
We now need to iterate through the smallest set, knowing that it might either be a RedisSet or a RedisSortedSet. RedisSet already has an each method, which we created in the previous chapter, but we’re adding one on RedisSortedSet here. Both are pretty similar, they need to know how to iterate over the underlying data structure, in this case either a List or a ZSet. In the List case we use the new addition to the List class, each.
For the ZSet, we use its array attribute, which is a SortedArray, and call each on it, which is the “real” Array#each method, forwarding the block attribute to it, with the ampersand, because Ruby needs that for blocks. The array is sorted, so callers will receive the elements in the correct order.
Once we’re in the iteration itself, in the block, if we’re dealing with a RedisSet, then we won’t get a Pair instance at each iteration, and we’ll instead get a String, since RedisSet instances only store String instances as members. In this case we create a Pair, with a default score of BigDecimal(1).
Next we need to apply the weight value for that set to the score of the current member. While we might think that a multiplication with * would be enough, it’s actually not! We need to handle NaN values, such as 0 * inf. We do this with the accurately named Utils.multiply_or_zero_if_nan method. If applying a weight to a score results in NaN, we default to 0.
The next step of the intersection process is to iterate over all the other sets, and as soon as we find one that does not contain the current member of the smallest set, we stop and move on to the next element in the smallest set.
We start the iteration with sets_with_weight[1..-1], and we then extract the set and weight variable from the set_with_weight pair.
It is possible that the same set is reused multiple times in a ZINTER command, such as ZINTER 3 z1 z1 z1, and in this case we do not need to look the pair up in the other set. The variable pair, from the smallest set, is the same, so we set other_pair to pair, as a shortcut, to avoid a lookup in set.
Otherwise, we need to lookup pair in set, but set might a regular set or a sorted set. We test for the presence in a RedisSet instance with set.member?(pair.member), and if we find a match, we create a new Pair instance with a default score of 1, as we did earlier with the element from the smallest set.
If set is a RedisSortedSet, then we call the RedisSortedSet#find_pair method. The find_pair method behaves differently depending on the type of @underlying. If it is a ZSet, we use the get_entry method with its dict attribute, which performs an O(1) operation to retrieve the element from the sorted set, or nil. If there is a result we instantiate a new Pair instance with the score and member values from dict.
As we’ve already seen many times the List case is a bit more cumbersome and we delegate it to a private method. That method, list_find_pair, uses the List#each method to iterate through the list until it either reaches the end of the list or it finds a Pair instance in it for which its member attributes matches the member argument, which is an O(n) operation. Earlier we talked about why it was great that procs allowed us to return from the outer method, and this is a great example, it allows us to short-ciruit the iteration in the each method.
Back to the intersection class method, by now we either found other_pair in set, or not. If we failed to find it, we break from the loop and move to the next element in the smallest set while setting present_in_all_sets to false. This variable is necessary because when we exit the loop over all the other sets, we need to know whether the current element in the smallest set, pair should be added to the result set, and it should only be added if we did find it in all the other sets.
On the other hand, if other_pair is not nil, then we need to aggregate the scores, but first we need to apply the weight of the other set to other_pair, which we again use multiply_or_zero_if_nan for. The aggregation is delegated to the private class method aggregate_scores.
This method takes an aggregate symbol, either :min, :max or :sum and two numeric values. It uses a case/when to apply the correct function, using Utils.add_or_zero_if_nan as a safety measure because some additions might return NaN, such as inf - inf. Let’s add this method as well as multiply_or_zero_if_nan:
module BYORedis
module Utils
# ...
def self.multiply_or_zero_if_nan(a, b)
BigDecimal.save_exception_mode do
BigDecimal.mode(BigDecimal::EXCEPTION_NaN, true)
a * b
end
rescue FloatDomainError
BigDecimal(0)
end
def self.add_or_zero_if_nan(a, b)
add_or_raise_if_nan(a, b)
rescue FloatNaN
BigDecimal(0)
end
end
end
listing 10.33 The add_or_zero_if_nan & multiply_or_zero_if_nan methods
If the aggregate value is neither of the expected ones we follow the “this is not supposed to happen so throw a generic exception so that bugs are caught in the development cycle” approach.
As previously mentioned, once we exit the loop over all the other sets, we need to check why we exited it. Did we check all the sets and found pair in all of them? If so we need to add it, with the aggregated score, to the result set, intersection_set, otherwise, we can move on to the next member of the smallest set.
And with that, we’re now done, for real, with the ZINTER command.
Sorted Set Intersection, but store the result this time
ZINTERSTORE behaves almost exactly as ZINTER, with the only difference being that the first argument is the key where the result set will be stored and the return value is the cardinality of the new set.
The format is described as the following by the Redis documentation:
ZINTERSTORE destination numkeys key [key ...]
[WEIGHTS weight [weight ...]]
[AGGREGATE SUM|MIN|MAX]
Let’s create the ZInterStoreCommand class:
module BYORedis
module SortedSetUtils
# ...
def self.set_operation_store_command(db, args)
Utils.assert_args_length_greater_than(2, args)
destination_key = args.shift
result_set, _ = yield
if result_set.empty?
db.data_store.delete(destination_key)
else
db.data_store[destination_key] = result_set
end
RESPInteger.new(result_set.cardinality)
end
# ...
end
# ...
class ZInterStoreCommand < BaseCommand
def call
SortedSetUtils.set_operation_store_command(@db, @args) do
SortedSetUtils.intersection(@db, @args)
end
end
def self.describe
Describe.new('zinterstore', -4, [ 'write', 'denyoom', 'movablekeys' ], 0, 0, 0,
[ '@write', '@sortedset', '@slow' ])
end
end
# ...
end
listing 10.34 The ZInterStoreCommand class
Earlier we created the SortedSetUtils.set_operation_command method so we could share some of the logic between ZINTER and ZUNION, because they accept the same arguments, the only difference is that one performs an intersection and one a union. We’re doing the same here with SortedSetUtils.set_operation_store_command, so that we share some logic between ZINTERSTORE and ZUNIONSTORE, which are both similar to the non-store commands, but different because they accept an extra key, destination.
The set_operation_store_command checks that we have more than two arguments, the smallest list of arguments we can accept is destination, numkeys set to 1 and one key. We then call Array#shift, to extract the destination argument, and we end up with an argument list identical to what ZINTER accepts, so we use the exact same method in the SortedSetUtils module we did earlier, intersection.
The other difference is in how we handle the result of the intersection operation, instead of returning it to the client, we store it at destination_key, and we return its cardinality. This is what set_operation_store_command does once it received the result from yield. Note that we discard the withscores value because we’re not serializing the set. This command, like other *STORE commands deletes whatever was stored at destination if the result of the operation is empty. Redis never stores empty collection, but it clears the destination, to make the following sequence of operation sensible:
127.0.0.1:6379> SET a-string whatever
OK
127.0.0.1:6379> TYPE z
none
127.0.0.1:6379> ZINTERSTORE a-string 2 z z
(integer) 0
127.0.0.1:6379> ZCARD a-string
(integer) 0
The result of ZINTERSTORE is 0, telling us that the result set is empty, and it seems reasonable that calling ZCARD on it would also return 0, to keep things consistent. If Redis did not delete whatever might have already existed, the a-string key would still have been a string, and this is what we would have observed, which would have been very surprising for users:
127.0.0.1:6379> SET a-string whatever
OK
127.0.0.1:6379> TYPE z
none
127.0.0.1:6379> ZINTERSTORE a-string 2 z z
(integer) 0
127.0.0.1:6379> ZCARD a-string
(error) WRONGTYPE Operation against a key holding the wrong kind of value
Set Union
Like ZINTER, ZUNION is a recent addition to Redis and was added in 6.2.0.
ZUNION accepts the exact same options than ZINTER, the only difference being that it returns the set union instead of the set intersection.
module BYORedis
module SortedSetUtils
# ...
def self.union(db, args)
set_operation(db, args) do |sets_with_weight, aggregate|
RedisSortedSet.union(sets_with_weight, aggregate: aggregate)
end
end
# ...
end
# ...
class ZUnionCommand < BaseCommand
def call
SortedSetUtils.set_operation_command(@args) do
SortedSetUtils.union(@db, @args)
end
end
def self.describe
Describe.new('zunion', -3, [ 'readonly', 'movablekeys' ], 0, 0, 0,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.35 The ZUnionCommand class
We can already see some of the decisions we made earlier when implementing ZINTER paying off. The content of ZUnionCommand#call is really concise and very similar to ZInterCommand#call, the only difference is the content of the block passed to SortedSetUtils.set_operation_command, which is SortedSetUtils.union this time.
This method, SortedSetUtils.union is very similar to SortedSetUtils.intersection, it also calls SortedSetUtils.set_operation, which does the heavy lifting with regards to all the possible options, and calls RedisSortedSet.union instead:
module BYORedis
class RedisSortedSet
# ...
def self.union(sets_with_weight, aggregate: :sum)
return RedisSortedSet.new({}) if sets_with_weight.empty?
accumulator = Dict.new
sets_with_weight[0..-1].each do |set_with_weight|
set = set_with_weight[0]
weight = set_with_weight[1]
next if set.nil?
set.each do |set_member|
if set.is_a?(RedisSet)
pair = Pair.new(BigDecimal(1), set_member)
elsif set.is_a?(RedisSortedSet)
pair = set_member
else
raise "Unknown set type: #{ set }"
end
weighted_score = Utils.multiply_or_zero_if_nan(pair.score, weight)
existing_entry = accumulator.get_entry(pair.member)
if existing_entry
new_score = aggregate_scores(aggregate, existing_entry.value, weighted_score)
existing_entry.value = new_score
else
accumulator[pair.member] = weighted_score
end
end
end
union_set = RedisSortedSet.new
accumulator.each do |key, value|
union_set.add(value, key)
end
union_set
end
# ...
end
end
listing 10.36 The RedisSortedSet.union method
Set intersection was the complicated one, and we’ve kept the simpler version of the two for last. RedisSet.union was also the simplest of the set operations in the previous chapter, and it is the same here. We need to iterate through all the sets no matter what, there’s no shortcut here.
For each set member, we need to check what type of set it is, and give it the default score of 1 if it’s a “regular” set. We then weigh the scores, aggregate them, and throw the result in accumulator, a Dict. The use of a Dict here might be a bit surprising, because we need to return a RedisSortedSet after all. This is a small optimization because inserting in a Dict is cheaper on average than inserting in a RedisSortedSet. There might be a lot of insertions and updates required as we go through all the set members. It’s entirely possible that members change positions through the iteration, but we don’t care about maintaining the set sorted while we iterate, we only care about it at the end.
So we use a Dict, which is an efficient way to keep track of all the members, updating their scores is “cheap” as we can find the dict entry, update its score and move on, no re-ordering or anything.
Once the whole iteration is over, for all the sets, we convert the Dict to a RedisSortedSet, and we’re done!
Sorted Set Union stored instead of returned
Finally, ZUNIONSTORE is the union variant, which behaves similarly to ZINTERSTORE, let’s create the ZUnionStoreCommand class:
module BYORedis
# ...
class ZUnionStoreCommand < BaseCommand
def call
SortedSetUtils.set_operation_store_command(@db, @args) do
SortedSetUtils.union(@db, @args)
end
end
def self.describe
Describe.new('zunionstore', -4, [ 'write', 'denyoom', 'movablekeys' ], 0, 0, 0,
[ '@write', '@sortedset', '@slow' ])
end
end
end
listing 10.37 The ZUnionStoreCommand class
By now we’re already implemented all these methods! We’ve seen SortedSetUtils.set_operation_store_command when adding ZINTERSTORE and we’ve just seen SortedSetUtils.union when adding ZUNION. We can reuse the existing, and like Lego bricks, assemble them in a slightly different way and get what we need, sweet!
Done with set operations, next we’re going to move to a few utility commands returning information about sorted set members.
Member data retrieval commands
Redis supports some commands to retrieve information for one or more members in a sorted set. ZRANK returns the “rank”, that is the position as a zero-based index of the member in the sorted set, or a nil string if it is not present. ZSCORE & ZMSCORE are similar, with the difference that ZMSCORE accepts multiple members and returns an array, similar so SMISMEMBER in the previous chapter. As their name implies, they return the score of the given member(s).
Note that ZMSCORE is a recent addition in Redis 6.2.0.
Let’s start with the ZRankCommand class:
module BYORedis
# ...
class ZRankCommand < BaseCommand
def call
Utils.assert_args_length(2, @args)
sorted_set = @db.lookup_sorted_set(@args[0])
if sorted_set
RESPSerializer.serialize(sorted_set.rank(@args[1]))
else
NullBulkStringInstance
end
end
def self.describe
Describe.new('zrank', 3, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.38 The ZRankCommand class
The ZRANK command accepts two arguments, key and member, and nothing else, if we find a RedisSortedSet for key, we call the new RedisSortedSet#rank method:
module BYORedis
class RedisSortedSet
# ...
def rank(member)
case @underlying
when List then find_member_in_list(member) { |_, rank| rank }
when ZSet
entry = @underlying.dict.get_entry(member)
return nil unless entry
@underlying.array.index(Pair.new(entry.value, member))
else raise "Unknown type for #{ @underlying }"
end
end
private
# ...
def find_member_in_list(member)
index = 0
@underlying.each do |pair|
return yield pair, index if pair.member == member
index += 1
end
nil
end
end
end
listing 10.39 The RedisSortedSet#rank method
To retrieve the rank of a member in List, we start iterating from the left with each, and count, until we find it. The rank of an element is its 0-based index after all.
In a ZSet things are bit different. We could iterate through the sorted array, until we find the element we’re looking for, but the combination of the Dict and the SortedArray allow us to be more efficient!
We first call Dict#get_entry, to retrieve the Pair instance. This is already a big win, because if there is no entry, we can return nil right away, we know that there is no rank value to return. On the other hand, if we did find a member, the Dict itself cannot tell us its rank, because the Pair instances it stores are not ordered. We use the SortedArray for that, and because we have both the score and member values, we can leverage the sorted property to find the element faster than by having to iterate through the whole array, in O(logn) time. By knowing the score it’s looking for, the SortedArray#index method will use binary search, with the bsearch_index method, to get to the element in less steps.
The index returned by SortedArray#index happens to be the rank value, we found what we were looking for.
Next is the ZScoreCommand class:
module BYORedis
# ...
class ZScoreCommand < BaseCommand
def call
Utils.assert_args_length(2, @args)
sorted_set = @db.lookup_sorted_set(@args[0])
if sorted_set
RESPSerializer.serialize(sorted_set.score(@args[1]))
else
NullBulkStringInstance
end
end
def self.describe
Describe.new('zscore', 3, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.40 The ZScoreCommand class
The ZSCORE command has a similar structure to ZRANK, it takes two arguments, key and member. We need to add the RedisSortedSet#score method:
module BYORedis
class RedisSortedSet
# ...
def score(member)
case @underlying
when List then find_member_in_list(member) { |pair, _| pair.score }
when ZSet then @underlying.dict[member]
else raise "Unknown type for #{ @underlying }"
end
end
# ...
end
end
listing 10.41 The RedisSortedSet#score method
In the List case we use the same method we used earlier, find_member_in_list, and we return the score value of the element, if we find it.
Things are easier in the Dict case, compared to ZRANK, the result of Dict#[] will return the value we store in each DictEntry, which happens to be the score, remember the keys are the member values, because these are the ones we need to maintain uniqueness on.
So we have the score, we can return it.
And finally, let’s add the ZMScoreCommand class:
module BYORedis
# ...
class ZMScoreCommand < BaseCommand
def call
Utils.assert_args_length_greater_than(1, @args)
sorted_set = @db.lookup_sorted_set(@args[0])
scores = @args[1..-1].map do |member|
sorted_set.score(member) if sorted_set
end
RESPArray.new(scores)
end
def self.describe
Describe.new('zmscore', -3, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.42 The ZMScoreCommand class
ZMSCORE can use mostly the same approach we used in ZSCORE, with the difference being that we iterate over each member we received in the argument list, and call RedisSortedSet#score for each of them, within a block given to Array#map so that the return value is a map of scores, potentially containing nil values.
Remove commands
Redis provides different ways to remove members from a sorted set. In this section we’ll implement the ZREM, ZREMRANGEBYLEX, ZREMRANGEBYRANK & ZREMRANGEBYSCORE commands. Four other commands also remove members from sorted sets, ZPOPMIN & ZPOPMAX as well as their blocking variants, we’ll explore these later in the chapter.
We’ll add ZREM first:
module BYORedis
# ...
class ZRemCommand < BaseCommand
def call
Utils.assert_args_length_greater_than(1, @args)
sorted_set = @db.lookup_sorted_set(@args.shift)
removed_count = 0
if sorted_set
@args.each do |member|
removed_count += 1 if sorted_set.remove(member)
end
end
RESPInteger.new(removed_count)
end
def self.describe
Describe.new('zrem', -3, [ 'write', 'fast' ], 1, 1, 1,
[ '@write', '@sortedset', '@fast' ])
end
end
end
listing 10.43 The ZRemCommand class
ZREM accepts one or more members, so we iterate over all of them, after shifting the key argument from the argument array. For each member, we call RedisSortedSet#remove and increment a counter if it returned true. Let’s add this method:
module BYORedis
class RedisSortedSet
# ...
def remove(member)
case @underlying
when List then remove_list(member)
when ZSet then @underlying.remove_member(member)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def remove_list(member)
iterator = List.left_to_right_iterator(@underlying)
while iterator.cursor
if iterator.cursor.value.member == member
@underlying.remove_node(iterator.cursor)
return true
end
iterator.next
end
false
end
end
end
listing 10.44 The RedisSortedSet#remove method
In the List case, as has been the case a few times already, we delegate the work to a private method remove_list. In this method we iterate from left to right, until we find the member we’re looking for. If we don’t find it, we return false, to notify the caller that nothing was deleted.
If we do find the member, we call List#remove_node with the node we get from the iterator variable to remove the member from the list.
This is a rare case where we don’t use the List#each method because we need a direct reference to the node value to pass to List#remove_node, and the each method skips over it to return the value the node contains, so we need a little bit more control here and use the lower level approach.
In the Dict case, we call the Dict#remove_member method. This method needs to make sure that both internal collections, the Dict and the SortedArray are updated and no longer contain the member, if it was present.
module BYORedis
class ZSet
# ...
def remove_member(member)
entry = @dict.delete_entry(member)
return false unless entry
index = @array.index(new_pair(entry.value, member))
@array.delete_at(index)
true
end
# ...
end
end
listing 10.45 The ZSet#remove_member method
We start by calling Dict#delete_entry, which will return false if it fails to find the key we’re looking for, or the entry that was removed if it contained it.
With the value attribute of the entry variable, which is the score of the member, we can call SortedArray#index method, and it will efficiently find the index, that is, without a full scan of the array. Now that we have the index value, we can call delete_at to remove this Pair from the array.
And with that the ZSet is now updated and the member is completely removed.
Rank Ranges
We are now going to add the ZREMRANGEBYRANK command, which has the following format according to the Redis documentation:
ZREMRANGEBYRANK key start stop
start and stop must be valid integers and negative values count as starting from the last member, the one with the highest score. The semantics are equivalent the the ones used in the ZRANGE command. The return value is the number of deleted members.
module BYORedis
# ...
class ZRemRangeByRankCommand < BaseCommand
def call
Utils.assert_args_length(3, @args)
start = Utils.validate_integer(@args[1])
stop = Utils.validate_integer(@args[2])
sorted_set = @db.lookup_sorted_set(@args[0])
removed_count = 0
if sorted_set
range_spec =
RedisSortedSet::GenericRangeSpec.rank_range_spec(start, stop, sorted_set.cardinality)
removed_count = sorted_set.remove_rank_range(range_spec)
end
RESPInteger.new(removed_count)
end
def self.describe
Describe.new('zremrangebyrank', 4, [ 'write' ], 1, 1, 1,
[ '@write', '@sortedset', '@slow' ])
end
end
end
listing 10.46 The ZRemRangeByRankCommand class
Validating the number of arguments, checking that start and stop are both valid integers and looking up the set, once all these steps are successfully completed, we call remove_rank_range on the sorted set, which is a new method:
module BYORedis
class RedisSortedSet
# ...
def remove_rank_range(range_spec)
return 0 if range_spec.empty? || no_overlap_with_range?(range_spec) { |_, rank| rank }
case @underlying
when List then remove_rank_range_list(range_spec)
when ZSet then @underlying.remove_rank_range(range_spec.min, range_spec.max)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def remove_rank_range_list(range_spec)
generic_remove_range_list(range_spec) { |_, rank| rank }
end
def generic_remove_range_list(range_spec)
removed_count = 0
iterator = List.left_to_right_iterator(@underlying)
entered_range = false
rank = 0
while iterator.cursor
pair = iterator.cursor.value
in_range = range_spec.in_range?(yield(pair, rank))
if in_range
entered_range ||= true
removed_count += 1
next_node = iterator.cursor.next_node
@underlying.remove_node(iterator.cursor)
iterator.cursor = next_node
elsif entered_range
break
else
iterator.next
end
rank += 1
end
removed_count
end
end
end
listing 10.47 The RedisSortedSet#remove_rank_range method
We already used no_overlap_with_range? earlier, when serializing sub ranges of sorted sets in SortedSetSerializerBy, which is used for both ZRANGEBYSCORE and ZRANGEBYLEX. We can also use it here, since there won’t be anything to remove for a rank range that is completely outside the set. For instance, the range 5 10 would not have any overlap with the sorted set { < 1, 'a' >, < 2, 'b' > }. This sorted set only contains two elements, with ranks 0 and 1. This is why we made no_overlap_with_range? calls its block argument with two arguments, the Pair, and the rank, this lets the block we pass from remove_rank_range tell the range to use the rank values to compare elements: return 0 if range_spec.empty? || no_overlap_with_range?(range_spec) { |_, rank| rank }.
The List branch delegates to the remove_rank_range_list private method, and the ZSetone to a method in that class, let’s stay in RedisSortedSet for now and look at the list case.
The process to delete a range, whether it’s a rank range, a score range or a lex range is very similar, so we create the generic_remove_range_list method to encapsulate the logic. The only thing the method needs, beside a range spec, is a block that tells it what to consider when sorting elements, the score, the member, or the rank. In this case, we pass a block that tells it to use the rank: { |_, rank| rank }. The range_spec we pass is the one we received from the ZRemRangeByRankCommand#call.
In generic_remove_range_list we iterate from left to right, with a few additional variables to keep track of where we are in the set. removed_count is necessary since this is what we need to return, entered_range is a helper like we’ve seen earlier that we’ll use to abort before the end of the set if we can, and rank is necessary to yield it to the given block.
For each element we encounter, we ask the range_spec variable if it is in the range, using the result from yield(pair, rank), which in this case always returns the rank value. Note how we once again use a method that does not specifically know what to call, .score, .member or something else, and instead relies on a block to parameterize its behavior.
If the member is in range, we flag that we’ve entered the range with entered_range ||= true, increment removed_count, delete the node from the list, and tell the iterator to move to the next node.
If the member is not in the range, but we’ve entered the range, it means we just exited it, and we can exit the loop, otherwise, we haven’t entered the range yet so we need to keep iterating. Finally, we increment the rank before jumping to the next loop iteration.
Once we exit the while loop, we return removed_count. This is another instance where we need a direct reference to the ListNode object and therefore need to use an iterator instead of List#each.
Let’s now take a look at hew ZSet#remove_rank_range method. It accepts two arguments, the start and stop values, which happen to map directly to the index of the elements in the SortedArray. This lets us use the Array#slice! method to delete the whole range, which returns the deleted elements. We then iterate over the deleted elements to also remove the entries in the Dict.
module BYORedis
class ZSet
# ...
def remove_rank_range(start, stop)
removed = @array.slice!(start..stop)
return 0 if removed.nil?
removed.each do |pair|
@dict.delete(pair.member)
end
removed.size
end
# ...
end
end
listing 10.48 The ZSet#remove_rank_range method
Lex Ranges
Next is ZREMRANGEBYLEX, which has the following format according to the Redis documentation:
ZREMRANGEBYLEX key min max [LIMIT offset count]
We’ll need to handle a lex range in the same way we did with ZRANGEBYLEX earlier, let’s create the ZRemRangeByLexCommand class:
module BYORedis
# ...
class ZRemRangeByLexCommand < BaseCommand
def call
Utils.assert_args_length(3, @args)
range_spec = Utils.validate_lex_range_spec(@args[1], @args[2])
sorted_set = @db.lookup_sorted_set(@args[0])
removed_count = 0
if sorted_set
removed_count = sorted_set.remove_lex_range(range_spec)
end
RESPInteger.new(removed_count)
end
def self.describe
Describe.new('zremrangebylex', 4, [ 'write' ], 1, 1, 1,
[ '@write', '@sortedset', '@slow' ])
end
end
end
listing 10.49 The ZRemRangeByLexCommand class
The min and max values use the same format used in ZRANGEBYLEX, so we reuse the validate_lex_range_spec method from the Utils module. We pass the range spec it returns, which is a range spec aware of the specificities of lex comparisons, created with GenericRangeSpec.lex_range_spec. Let’s add the remove_lex_range to RedisSortedSet:
module BYORedis
class RedisSortedSet
# ...
def remove_lex_range(range_spec)
return 0 if range_spec.empty? ||
no_overlap_with_range?(range_spec) { |pair, _| pair.member }
case @underlying
when List then remove_lex_range_list(range_spec)
when ZSet then @underlying.remove_lex_range(range_spec)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def remove_lex_range_list(range_spec)
generic_remove_range_list(range_spec) { |pair, _| pair.member }
end
end
end
listing 10.50 The RedisSortedSet#remove_lex_range method
The method starts almost identically to remove_rank_range, with the exception that this time we tell no_overlap_with_range? to use the member attribute from the pair variable, instead of the rank variable.
The List case delegates to the remove_lex_range_list private method, which also uses the generic_remove_range_list private method, like remove_rank_range_list did, but tells it to use the pair.member value, instead of the rank, to decide what to remove from the list. This is another example of the benefits of generic_remove_range_list being so abstract, we can now express remove_lex_range_list very succinctly, and let generic_remove_range_list do the heavy lifting, removing elements from the list, counting the number of elements deleted, and so on.
For the ZSet case, things are not as simple because this time we do not have the index values of the elements we need to delete like we had for ZREMRANGEBYRANK, let’s create the remove_lex_range method:
module BYORedis
class ZSet
# ...
def remove_lex_range(range_spec)
generic_remove(range_spec, &:member)
end
private
# ...
def generic_remove(range_spec, &block)
first_in_range_index = @array.first_index_in_range(range_spec, &block)
last_in_range_index = first_in_range_index
(first_in_range_index.upto(@array.size - 1)).each do |rank|
pair = @array[rank]
in_range = range_spec.in_range?(yield(pair))
if in_range
last_in_range_index = rank
else
break
end
end
remove_rank_range(first_in_range_index, last_in_range_index)
end
end
end
listing 10.51 The ZSet#remove_lex_range method
remove_lex_range uses the generic_remove method, which we’ll be able to use when removing score ranges. We use first_index_in_range, from SortedArray, which we’ve added earlier when serializing ranges in ZRANGEBYLEX and ZRANGEBYSCORE. By giving the block that returns the member attribute of a Pair instance, first_index_in_range will be able to find the first element in the array that is in the range.
Once we found this element, we iterate from there, and as long as elements are in the range, we mark the current index as the last index of elements in range with last_in_range_index. As soon as we find an element that is not in range, we exit the loop.
At this point, we have the boundaries of the range we need to delete, in terms of indices, the index of the first element, which first_index_in_range gave us, and the last index, last_in_range_index, which we found by iterating through the array. These values are also ranks, since the rank is the index of the element in the set, meaning that we can use the remove_rank_range we added earlier when adding the ZREMRANGEBYRANK method. This method items from @array and @dict, and return the number of elements deleted, so we can return what it returns.
Score Ranges
And finally we are adding ZRemRangeByScoreCommand, for the ZREMRANGEBYSCORE command, which has the following format according to the Redis Documentation:
ZREMRANGEBYSCORE key min max
min and max must be valid scores, with the same semantics as in ZRANGEBYSCORE where a score can be marked as exclusive with the ( prefix.
module BYORedis
# ...
class ZRemRangeByScoreCommand < BaseCommand
def call
Utils.assert_args_length(3, @args)
range_spec = Utils.validate_score_range_spec(@args[1], @args[2])
sorted_set = @db.lookup_sorted_set(@args[0])
removed_count = 0
removed_count = sorted_set.remove_score_range(range_spec) if sorted_set
RESPInteger.new(removed_count)
end
def self.describe
Describe.new('zremrangebyscore', 4, [ 'write' ], 1, 1, 1,
[ '@write', '@sortedset', '@slow' ])
end
end
end
listing 10.52 The ZRemRangeByScoreCommand class
We reuse the validate_score_range_spec method from the Utils module, to create the right type of range, a GenericRangeSpec created with score_range_spec, we then pass this range spec to RedisSortedSet#remove_score_range:
module BYORedis
class RedisSortedSet
# ...
def remove_score_range(range_spec)
return 0 if range_spec.empty? ||
no_overlap_with_range?(range_spec) { |pair, _| pair.score }
case @underlying
when List then remove_score_range_list(range_spec)
when ZSet then @underlying.remove_score_range(range_spec)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def remove_score_range_list(range_spec)
generic_remove_range_list(range_spec) { |pair, _| pair.score }
end
end
end
listing 10.53 The RedisSortedSet#remove_score_range method
The structure of the method might look pretty familiar by now, this is almost identical to remove_lex_range, with the exception of the block given to no_overlap_with_range? which returns the score attribute this time.
In the List case we call remove_score_range_list, which itself uses the generic_remove_range_list, with a block telling it to extract the score attribute from the Pair instances it handles.
For ZSet instances, we call remove_score_range, which can be expressed in terms of the method we just wrote earlier for ZREMRANGEBYLEX, generic_remove:
module BYORedis
class ZSet
# ...
def remove_score_range(range_spec)
generic_remove(range_spec, &:score)
end
# ...
end
end
listing 10.54 The ZSet#remove_score_range method
With ZREMRANGEBYSCORE we have now implemented all the *REM* methods, next up, the *REV* variants. Did you notice how we did not have to write any real logic this time, we just called a few existing methods with the right block telling them what values to extract!
Reverse commands
All the commands we’ve implemented so far used an implicit sorting order by ascending score. Redis provides four commands that let users reverse the order and use the scores in descending order: ZREVRANGE, ZREVRANGEBYLEX, ZREVRANGEBYSCORE, & ZREVRANK. These commands behave almost identically to ZRANGE, ZRANGEBYLEX, ZRANGEBYSCORE & ZRANK, all of which were implemented earlier in the chapter, but use the reverse score ordering instead.
We’ve spent some time earlier explaining why we were building things in a way that may have look convoluted, well, now we’re about to see why. These commands will all be really short to write, because most of the logic already exists, we just have to reverse things in a few places, here and there.
Let’s start with the ZREVRANGE command, which has the following format according to the Redis Documentation:
ZREVRANGE key start stop [WITHSCORES]
Let’s create the ZRevRangeCommand class:
module BYORedis
# ...
class ZRevRangeCommand < BaseCommand
def call
SortedSetUtils.generic_range(@db, @args, reverse: true)
end
def self.describe
Describe.new('zrevrange', -4, [ 'readonly' ], 1, 1, 1, [ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.55 The ZRevRangeCommand class
We call the generic_range method we created earlier, but this time we set the reverse flag to true. The flag is used to decide in which order to handle the start and stop argument. We use a trick to convert start and stop in a way that will make it easy to reuse, before looking at the code, which is convoluted, let’s first look at an example with the following sorted set:
127.0.0.1:6379> ZADD z 10 a 15 c 20 f 50 m 100 z
(integer) 5
127.0.0.1:6379> ZRANGE z 0 -1
1) "a"
2) "c"
3) "f"
4) "m"
5) "z"
127.0.0.1:6379> ZRANGE z 2 3
1) "f"
2) "m"
127.0.0.1:6379> ZREVRANGE z 0 -1
1) "z"
2) "m"
3) "f"
4) "c"
5) "a"
127.0.0.1:6379> ZREVRANGE z 2 3
1) "f"
2) "c"
With ZRANGE, the members a, c, f, m, & z have the ranks 0, 1, 2, 3 & 4, with ZREVRANGE, a has now the rank 4, c 3, f, 2, m 1 and z 0.
It turns out that we can always convert a “regular index” to a reversed index with the following logic:
- if index is greater than or equal to 0, convert it to the maximum index minus the index value
- if index is negative, convert it to the maximum index value, minus the sum of the index, the maximum index value, and 1
Yup, that works, let’s look at the values we used in the example above and start with 0, its “reverse equivalent” is 4, that is when we pass 0 to ZREVRANGE, we can get the desired value by fetching the element at rank 4 in the sorted set, which is where z is, at index 4 in the set, and ZREVRANGE z 0 0 does return z.
We apply the first rule, where max index is 4, the max rank in the set, so 4 - 0 = 0, 4 is indeed the index in the set where we would find z.
Let’s keep going, with a negative value this time, -1, in the set, this is the last index, the member z, when passed to ZREVRANGE, -1 maps to a, which is the member at index 0 in the sorted set, so -1 should give us 0 back. Let’s check, it applies to the second rule, 4 - (-1 + 4 + 1) = 0, it worked again!
Let’s check 2 and 3 now, in the set, they return the members f and m, but in ZREVRANGE, they respectively map to f and c, which are the members at index 2 and 1 in the set, so 2 should stay 2 and 3 should become 1. They both trigger the first rule: 4 - 2 = 2 and 4 - 3 = 1.
These examples show us that we can apply these transformations to know where to look in the sorted set. For instance when we receive the command ZREVRANGE z 2 3, we’ll transform start from 2 to 2 and stop from 3 to 1, we can then swap start and stop, so that we maintain the condition start <= stop and we’re almost done. The last thing is that we now need to tell the serializer to serialize the items from right to left.
In ZREVRANGE 0 -1, both boundaries will be converted to 4 and 0, and then swapped so that start is 0 and stop is 4.
Let’s make these changes:
module BYORedis
module SortedSetUtils
# ...
def self.generic_range(db, args, reverse: false)
Utils.assert_args_length_greater_than(2, args)
start = Utils.validate_integer(args[1])
stop = Utils.validate_integer(args[2])
raise RESPSyntaxError if args.length > 4
if args[3]
if args[3].downcase == 'withscores'
withscores = true
else
raise RESPSyntaxError
end
end
sorted_set = db.lookup_sorted_set(args[0])
if reverse
tmp = reverse_range_index(start, sorted_set.cardinality - 1)
start = reverse_range_index(stop, sorted_set.cardinality - 1)
stop = tmp
end
if sorted_set
range_spec =
RedisSortedSet::GenericRangeSpec.rank_range_spec(start, stop, sorted_set.cardinality)
SortedSetRankSerializer.new(
sorted_set,
range_spec,
withscores: withscores,
reverse: reverse,
)
else
EmptyArrayInstance
end
end
def self.reverse_range_index(index, max)
if index >= 0
max - index
elsif index < 0
max - (index + max + 1)
end
end
# ...
end
# ...
end
listing 10.56 The generic_range class method for the SortedSetUtils module
If the reverse flag is true we convert the indices as described earlier and we swap the values to maintain the order of start and stop. We propagate the reverse flag to SortedSetRankSerializer:
module BYORedis
# ...
class SortedSetRankSerializer
# ...
private
def serialize_zset
sub_array = @sorted_set.underlying.array[@range_spec.min..@range_spec.max]
members = []
sub_array.each do |pair|
if @reverse
members.prepend(Utils.float_to_string(pair.score)) if @withscores
members.prepend(pair.member)
else
members.push(pair.member)
members.push(Utils.float_to_string(pair.score)) if @withscores
end
end
RESPArray.new(members).serialize
end
def serialize_list
ltr_acc = lambda do |value, response|
response << RESPBulkString.new(value.member).serialize
if @withscores
response << RESPBulkString.new(Utils.float_to_string(value.score)).serialize
end
@withscores ? 2 : 1
end
rtl_acc = lambda do |value, response|
if @withscores
response.prepend(RESPBulkString.new(Utils.float_to_string(value.score)).serialize)
end
response.prepend(RESPBulkString.new(value.member).serialize)
@withscores ? 2 : 1
end
if @reverse
tmp = ltr_acc
ltr_acc = rtl_acc
rtl_acc = tmp
end
ListSerializer.new(@sorted_set.underlying, @range_spec.min, @range_spec.max)
.serialize_with_accumulators(ltr_acc, rtl_acc)
end
# ...
end
end
end
listing 10.57 The serialize_zset & serialize_list methods for the SortedSetRankSerializer class
In the serialize_list method we look at the @reverse flag and if it set to true we swap the values or ltr_acc and rtl_acc. Swapping these values has the effect of reverting the order in which elements get serialized. Looking again at the ZREVRANGE z 0 -1 example from earlier, where the desired result is z, m, f, c, a, the ListSerializer will iterate from 0 to 4, but instead of appending elements as it finds them, it’ll prepend them. It will first find a, at index 0, and will add it to the string serializing the resp array, and it will then find c, prepending it and so on, until it prepends z. If scores are to be included, it knows how to do that as well, the same way we did earlier for ZRANGE.
The process is similar in the ZSet case, if the @reverse flag is set to true, we use members.prepend instead of members.<< to accumulate elements.
Reverse Range by Score and Lex
ZREVRANGEBYLEX
Next is the ZREVRANGEBYLEX command, which has the following format according to the Redis Documentation:
ZREVRANGEBYLEX key max min [LIMIT offset count]
min and max have the same format we used in the ZRANGEBYLEX and ZREMRANGEBYLEX commands, and note how their order is reversed, the max boundary is specified first here.
module BYORedis
# ...
class ZRevRangeByLexCommand < BaseCommand
def call
SortedSetUtils.generic_range_by_lex(@db, @args, reverse: true)
end
def self.describe
Describe.new('zrevrangebylex', -4, [ 'readonly' ], 1, 1, 1,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.58 The ZRevRangeByLexCommand class
We call generic_range_by_lex, but this time we set the reverse flag to true, which changes how the arguments are read:
module BYORedis
module SortedSetUtils
# ...
def self.generic_range_by_lex(db, args, reverse: false)
# A negative count means "all of them"
options = { offset: 0, count: -1 }
Utils.assert_args_length_greater_than(2, args)
key = args.shift
if reverse
max = args.shift
min = args.shift
else
min = args.shift
max = args.shift
end
range_spec = Utils.validate_lex_range_spec(min, max)
parse_range_by_lex_options(args, options) unless args.empty?
sorted_set = db.lookup_sorted_set(key)
if options[:offset] < 0
EmptyArrayInstance
elsif sorted_set
options[:withscores] = false
options[:reverse] = reverse
SortedSetSerializerBy.new(sorted_set, range_spec, **options, &:member)
else
EmptyArrayInstance
end
end
# ...
end
# ...
end
listing 10.59 The generic_range_by_lex class method for the SortedSetUtils module
We read min and max in the reverse order, max first if reverse is true, and this is the only difference. The reverse flag is forwarded to SortedSetSerializerBy when we call it: SortedSetSerializerBy.new(sorted_set, range_spec, **options, &:member)
We ignored it earlier, but looking at the @reverse branch of the serialize_zset method in SortedSetSerializerBy, we now need a new method in SortedArray, last_index_in_range:
module BYORedis
# ...
class SortedSetSerializerBy
# ...
def serialize_zset
members = []
if @reverse
start_index = @sorted_set.underlying.array.last_index_in_range(@range_spec, &@block)
if start_index.nil?
raise "Unexpectedly failed to find last index in range for #{ self }"
end
indices = start_index.downto(0)
else
start_index = @sorted_set.underlying.array.first_index_in_range(@range_spec, &@block)
if start_index.nil?
raise "Unexpectedly failed to find first index in range for #{ self }"
end
indices = start_index.upto(@sorted_set.cardinality - 1)
end
# ...
end
def serialize_list
if @reverse
iterator = List.right_to_left_iterator(@sorted_set.underlying)
else
iterator = List.left_to_right_iterator(@sorted_set.underlying)
end
members = []
entered_range = false
while iterator.cursor && @count != 0
member = iterator.cursor.value
if @range_spec.in_range?(@block.call(member))
entered_range ||= true
if @offset == 0
members << member.member
members << Utils.float_to_string(member.score) if @withscores
@count -= 1
else
@offset -= 1
end
elsif entered_range == true
break
end
iterator.next
end
RESPArray.new(members).serialize
end
end
end
listing 10.60 The serialize_zset & serialize_list methods in the SortedSetSerializerBy class
Let’s look at serialize_zset first. The order of the range items is still what we’d expect, that is @range_spec.max is expected to be greater than or equal to @range_spec.min, using lexicographic order, but the “first” item in what we want to return is not the first item in the set to match the range, it’s the last one. Let’s look at an example:
127.0.0.1:6379> ZADD z 0 a 0 b 0 c 0 d 0 e 0 f
(integer) 6
127.0.0.1:6379> ZRANGEBYLEX z - +
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> ZREVRANGEBYLEX z + -
1) "f"
2) "e"
3) "d"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> ZREVRANGEBYLEX z [e [b
1) "e"
2) "d"
3) "c"
4) "b"
The set z has the elements a, b, c, d, e and f. When we request the range + -, we get the whole set, starting from the member with the greater value in lexicographic order, z, down to the smallest one, a. The next example is what interests us here, the range is [e [b, that is, from e, to b, inclusive. But remember that the range spec always needs to maintain the condition min <= max, so the range spec we created is actually one where min is b, and max is e, because we read the arguments in the reversed order, max first.
The layout of the SortedSet is roughly the following, ignoring the score since they’re all 0:
["a", "b", "c", "d", "e", "f"]
If we were to call first_index_in_range with the range spec for [b [e, we’d get 1, the index of b, but since we need to return e, d, c, b, the first index we want is 4, the index of e. This is why we call last_index_in_range, it’ll give us just what we need. And once we have the index of the last index, which is where we want to start iterating from, we create an enumerator that goes the other way, down to 0, with start_index.downto(0).
The rest of the method is the same, we iterate over all the indices in the range, we check if the item is in the range, and as soon as we find an item that is not, we exit the loop, while taking into account the values of @count and @offset.
Let’s take a look at the last_index_in_range method:
module BYORedis
class SortedArray
# ...
def last_index_in_range(range_spec)
return nil if empty?
first_index_outside = @underlying.bsearch_index do |existing_element|
compare = range_spec.compare_with_max(yield(existing_element))
if range_spec.max_exclusive?
compare >= 0 # existing_element.score > max
else
compare > 0 # existing_element.score >= max
end
end
case first_index_outside
when nil then @underlying.size - 1 # last
when 0 then nil # the max of the range is smaller than the smallest item
else first_index_outside - 1
end
end
end
end
listing 10.61 The SortedArray#last_index_in_range method
We use bsearch_index in a similar way we used it in first_index_in_range with a few differences. We compare each value with compare_with_max instead of compare_with_min, and the condition related to the exclusivity of the max boundary are reversed. Once again, it’s easier to look at an example in irb:
irb(main):001:0> set = [ 'a', 'b', 'c', 'd', 'e', 'f' ]
irb(main):002:0> set.bsearch_index { |x| x >= 'e' }
=> 4
irb(main):003:0> set.bsearch_index { |x| x > 'e' }
=> 5
irb(main):004:0> set.bsearch_index { |x| x >= 'f' }
=> 5
irb(main):005:0> set.bsearch_index { |x| x > 'f' }
=> nil
In all the examples we get the leftmost index, if it exists, for which the condition is true, in the first case, the smallest index where the value is greater than or equal to e is 4, because set[4] == 'e', and if we swap the condition to be strict, then it return 5, because the element at index 5, f, is the first one to be strictly greater than e. If we translate that to the inclusive/exclusive cases we’re trying to handle, we can see that the result are almost what we want, just off by one to the right. If the upper boundary is exclusive, (e, then the last index would be 3, and if it is inclusive, [e, then it would be 4. We can obtain these values by using the >= operator in the exclusive case and the > operator in the inclusive case, and subtracting one to the result.
There’s a small edge case we need to handle, what if the set does not contain an element that is outside the set, then the last element in the set would be the last in the range. This is what the last example above demonstrates, the set array does not contain a value greater than f, and returns nil, and in this case, because we have nothing we can subtract 1 to to obtain the last index, we need to handle this specific case.
This logic is what the case/when conditions at the end of last_index_in_range handle. There is also a special case where the value returned would be 0, in which case we don’t want to return -1 and want to return 0 instead. The following is an example that could potentially trigger this path but that will be prevented in practice by the no_overlap_with_range? check.
irb(main):011:0> '0' < 'a' # this is included as a reminder that in lex order '0' < 'a'
=> true
irb(main):012:0> set.bsearch_index { |x| x >= '0' }
=> 0
irb(main):013:0> set.bsearch_index { |x| x > '0' }
=> 0
In both cases the range does not overlap with the set, the max value of the range, '0' is lower than the mininum value of the set, 'a', and we return nil, none of the set members is within the range.
ZREVRANGEBYSCORE
Next is the ZREVRANGEBYSCORE command, which has the following format according to the Redis Documentation:
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
min and max have the same format we used in the ZRANGEBYSCORE and ZREMRANGEBYSCORE commands, and note how their order is reversed, the max boundary is specified first.
We’ll first create the ZRevRangeByScoreCommand class:
module BYORedis
# ...
class ZRevRangeByScoreCommand < BaseCommand
def call
SortedSetUtils.generic_range_by_score(@db, @args, reverse: true)
end
def self.describe
Describe.new('zrevrangebyscore', -4, [ 'readonly' ], 1, 1, 1,
[ '@read', '@sortedset', '@slow' ])
end
end
end
listing 10.62 The ZRevRangeByScoreCommand class
We call generic_range_by_score with the reverse flag set to true, let’s look at how the flag is handled in generic_range_by_score:
module BYORedis
module SortedSetUtils
# ...
def self.generic_range_by_score(db, args, reverse: false)
# A negative count means "all of them"
options = { offset: 0, count: -1, withscores: false }
Utils.assert_args_length_greater_than(2, args)
key = args.shift
if reverse
max = args.shift
min = args.shift
else
min = args.shift
max = args.shift
end
# ...
end
# ...
end
# ...
end
listing 10.63 Handling of the reverse flag in the SortedSetUtils.generic_range_by_score class method
Things are very similar to generic_range_by_lex, if reverse is true, we read max first, and we then create the range spec with these values.
And that’s it … yes, everything else “just works”. The code path is essentially the same as in ZRANGEBYSCORE, but the reverse flag will make sure that either the List or the ZSet are serialized in the reverse order, returning the desired result to the client.
ZREVRANK
ZREVRANK is simpler since it only deals with a single set member and returns its rank as if the set was sorted from highest scores to lowest:
127.0.0.1:6379> ZADD z 0 a 0 b 0 c 0 d 0 e 0 f
(integer) 6
127.0.0.1:6379> ZRANGE z 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> ZRANK z a
(integer) 0
127.0.0.1:6379> ZRANK z e
(integer) 4
127.0.0.1:6379> ZREVRANGE z 0 -1
1) "f"
2) "e"
3) "d"
4) "c"
5) "b"
6) "a"
127.0.0.1:6379> ZREVRANK z a
(integer) 5
127.0.0.1:6379> ZREVRANK z e
(integer) 1
Let’s create the ZRevRankCommand class:
module BYORedis
# ...
class ZRevRankCommand < BaseCommand
def call
Utils.assert_args_length(2, @args)
sorted_set = @db.lookup_sorted_set(@args[0])
if sorted_set
RESPSerializer.serialize(sorted_set.rev_rank(@args[1]))
else
NullBulkStringInstance
end
end
def self.describe
Describe.new('zrevrank', 3, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.64 The ZRevRankCommand class
We nee to add the rev_rank method in RedisSortedSet:
module BYORedis
class RedisSortedSet
# ...
def rev_rank(member)
member_rank = rank(member)
cardinality - 1 - member_rank if member_rank
end
# ...
end
end
listing 10.65 The RedisSortedSet#rev_rank method
We don’t need to change the order of the set to get the reversed rank of a member, we can use its “regular” rank, that we get with rank(member) and subtract it to the the cardinality of the set, and subtract one to that.
With the example from above, the rank of a in the set is 0, and the cardinality of z is 6, 6 - 0 - 1 == 5, the correct result. It also works for e, which has a rank of 4 and a “revrank” of 1: 6 - 4 - 1 == 1.
Pop Commands
We mentioned earlier the pop commands as ways to remove members from a sorted set. ZPOPMIN removes the element with the lowest score, and returns it and ZPOPMAX does the same with the member with the highest score.
Similarly to how we implemented BLPOP, BRPOP and BRPOPLPUSH in Chapter 7, we are going to add the two blocking variants of ZPOPMIN & ZPOPMAX: BZPOPMIN & BZPOPMAX. The semantics are similar to the blocking list commands, a timeout is given, where 0 means infinite, and the server will block the client until a value can be returned or until the timeout expires.
The format of ZPOPMAX is the following according to the Redis Documentation:
ZPOPMAX key [count]
count must be an integer and has a default value of 1. Negative values are accepted but turn the command in a no-op since an array cannot have a negative number of items, so Redis always returns an empty array.
Let’s start with the ZPopMaxCommand class:
module BYORedis
module SortedSetUtils
# ...
def self.generic_zpop(db, args)
Utils.assert_args_length_greater_than(0, args)
key = args.shift
count = args.shift
raise RESPSyntaxError unless args.empty?
count = if count.nil?
1
else
Utils.validate_integer(count)
end
sorted_set = db.lookup_sorted_set(key)
popped = []
if sorted_set
popped = db.generic_pop(key, sorted_set, count) do
yield sorted_set, count
end
end
RESPArray.new(popped)
end
end
# ...
class ZPopMaxCommand < BaseCommand
def call
SortedSetUtils.generic_zpop(@db, @args) do |sorted_set, count|
sorted_set.pop_max(count)
end
end
def self.describe
Describe.new('zpopmax', -2, [ 'write', 'fast' ], 1, 1, 1,
[ '@write', '@sortedset', '@fast' ])
end
end
end
listing 10.66 The ZPopMaxCommand class
We already know we have to implement two very similar commands, ZPOPMAX and ZPOPMIN, and both accept the same options, so we use the generic_zpop method to encapsulate all the logic that can be shared. The command handles the argument validation, as well as using a default value for count and calls yield with the sorted_set loaded from memory and the count value parsed an Integer. Elements are always returned with their scores when popped, so we’ll need to make sure to include when returning it. The popped variable is expected to be an array from the result of yield and is returned back to the client. Back in ZPopMaxCommand#call, we call RedisSortedSet#pop_max from the block with the variables given to us by generic_zpop.
And we now need to add the RedisSortedSet#pop_max method:
module BYORedis
class RedisSortedSet
# ...
def pop_max(count)
case @underlying
when List then generic_pop(count) { @underlying.right_pop&.value }
when ZSet
generic_pop(count) do
max = @underlying.array.pop
@underlying.dict.delete(max.member) if max
max
end
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def generic_pop(count)
popped = []
return popped if count < 0
while count > 0
min = yield
if min
popped.push(min.member, min.score)
count -= 1
else
break
end
end
popped
end
end
end
listing 10.67 The RedisSortedSet#pop_max method
Once again trying to always be one step ahead, we use a generic method that will be useful when implementing ZPOPMIN, generic_pop, to which we pass the count value.
This method handles the negative count scenario and returns an empty array right away in this case. Otherwise, it keeps iterating until count reaches 0, at each step we yield back to the caller, which in this case is either a call to @underlying.right_pop if we’re dealing with a List or @underlying.array.pop followed by a call to Dict#delete if we’re dealing with a ZSet. In either case, the Pair instance is returned and generic_pop aggregates it in popped, and decrements count. If the previous iteration deleted the last element in the set, we’ll receive nil from yield, and in this case we must stop iterating right away, there’s nothing else to pop.
Next up is ZPopMinCommand:
module BYORedis
# ...
class ZPopMinCommand < BaseCommand
def call
SortedSetUtils.generic_zpop(@db, @args) do |sorted_set, count|
sorted_set.pop_min(count)
end
end
def self.describe
Describe.new('zpopmin', -2, [ 'write', 'fast' ], 1, 1, 1,
[ '@write', '@sortedset', '@fast' ])
end
end
end
listing 10.68 The ZPopMinCommand class
The only different with ZPopMaxCommand is that the block given to generic_zpop calls pop_min instead of pop_max, let’s add the command to RedisSortedSet:
module BYORedis
class RedisSortedSet
# ...
def pop_min(count)
case @underlying
when List then generic_pop(count) { @underlying.left_pop&.value }
when ZSet
generic_pop(count) do
min = @underlying.array.shift
@underlying.dict.delete(min.member) if min
min
end
else raise "Unknown type for #{ @underlying }"
end
end
# ...
end
end
listing 10.69 The RedisSortedSet#pop_min method
The block we give to generic_pop is the one that actually performs the pop operation and in this case we use List#left_pop to remove the element with the smallest rank or Array#shift for a ZSet. We return the Pair instance in either case to let generic_pop handle everything for us and return the list of deleted pairs.
Blocking Commands
Both blocking commands have identical formats according to the Redis Documentation for BZPOPMIN:
BZPOPMIN key [key ...] timeout
and the Redis Documentation for BZPOPMAX
BZPOPMAX key [key ...] timeout
Let’s go ahead and add both classes, BZPopMaxCommand & BZPopMinCommand:
module BYORedis
module SortedSetUtils
# ...
def self.generic_bzpop(db, args, operation)
Utils.assert_args_length_greater_than(1, args)
timeout = Utils.validate_timeout(args.pop)
args.each do |set_name|
sorted_set = db.lookup_sorted_set(set_name)
next if sorted_set.nil?
popped = db.generic_pop(set_name, sorted_set, 1) do
yield sorted_set
end
return RESPArray.new([ set_name ] + popped)
end
Server::BlockedState.new(
BlockedClientHandler.timeout_timestamp_or_nil(timeout), args, operation)
end
end
# ...
class BZPopMaxCommand < BaseCommand
def call
SortedSetUtils.generic_bzpop(@db, @args, :zpopmax) do |sorted_set|
sorted_set.pop_max(1)
end
end
def self.describe
Describe.new('bzpopmax', -3, [ 'write', 'noscript', 'fast' ], 1, -2, 1,
[ '@write', '@sortedset', '@fast', '@blocking' ])
end
end
class BZPopMinCommand < BaseCommand
def call
SortedSetUtils.generic_bzpop(@db, @args, :zpopmin) do |sorted_set|
sorted_set.pop_min(1)
end
end
def self.describe
Describe.new('bzpopmin', -3, [ 'write', 'noscript', 'fast' ], 1, -2, 1,
[ '@write', '@sortedset', '@fast', '@blocking' ])
end
end
end
listing 10.70 The BZPopMinCommand & BZPopMaxCommand classes
Let’s ignore the blocking behavior for now, if any of sets for the given keys exist, we want to pop from it, either with pop_min or pop_max. We only need to pop one element so we set the count argument to 1 with .pop_min(1) and .pop_max(1). This is what we call from the block we give to generic_bzpop, but let’s look at what this method does in details. Once the timeout value is validated, we iterate over all the arguments one by one, each time we load the set, and jump to the next one if it’s nil. If it is not nil, we yield it back to the caller, which as we’ve just seen will call the appropriate pop method, and we exit the loop, returning the value that was popped. There’s no blocking behavior in this case.
In the case where we exhausted the list of all arguments, we want to block until one of these sets receives an element with ZADD, which is very similar to the BLPOP and BRPOP behavior, but with sorted sets this time.
We are going to reuse a lot of the BlockedClientHandler logic, but we need to make it aware of sorted sets now, back then it only knew about lists, but first we return an instance of BlockedState, with the result of timeout_timestamp_or_nil, a method we introduced in Chapter 7, that either converts the float timeout value by adding the value to the current time or return nil, indicating an infinite timeout. The last two arguments are args and operation. args has the all the sorted set keys, and operation is either the symbol :zpopmin or the symbol :zpopmax.
The server class already knows how to handle BlockedState instances with the block_client method, and will add it to its internal client_timeouts sorted array. Let’s take a a look at all the changes in the BlockedClientHandler class. As a reminder, the handle_client method is called from the Server class, from the handle_clients_blocked_on_keys method, which is called after each command is processed.
module BYORedis
class BlockedClientHandler
def initialize(server, db)
# ...
end
def self.timeout_timestamp_or_nil(timeout)
if timeout == 0
nil
else
Time.now + timeout
end
end
def handle(key)
clients = @db.blocking_keys[key]
list_or_set = @db.data_store[key]
raise "Unexpected empty list/sorted set for #{ key }" if list_or_set&.empty?
unblocked_clients = serve_client_blocked_on(key, list_or_set, clients)
@db.blocking_keys.delete(key) if clients.empty?
unblocked_clients
end
private
def pop_operation(key, list, operation, target)
case operation
when :lpop
RESPArray.new([ key, @db.left_pop_from(key, list) ])
when :rpop
RESPArray.new([ key, @db.right_pop_from(key, list) ])
when :rpoplpush
raise "Expected a target value for a brpoplpush handling: #{ key }" if target.nil?
ListUtils.common_rpoplpush(@db, key, target, list)
when :zpopmax
RESPArray.new([ key ] + @db.pop_max_from(key, list))
when :zpopmin
RESPArray.new([ key ] + @db.pop_min_from(key, list))
else
raise "Unknown pop operation #{ operation }"
end
end
def rollback_operation(key, response, operation, target_key)
case operation
when :lpop
element = response.underlying_array[1]
list = @db.lookup_list_for_write(key)
list.left_push(element)
when :rpop
element = response.underlying_array[1]
list = @db.lookup_list_for_write(key)
list.right_push(element)
when :rpoplpush
list = @db.lookup_list_for_write(key)
target_list = @db.lookup_list(target_key)
element = target_list.left_pop
@db.data_store.delete(target_key) if target_list.empty?
list.right_push(element.value)
when :zpopmax, :zpopmin
sorted_set = @db.lookup_sorted_set_for_write(key)
member = response.underlying_array[1]
score = response.underlying_array[2]
sorted_set.add(score, member)
else
raise "Unknown pop operation #{ operation }"
end
end
def handle_client(client, key, list_or_set)
blocked_state = client.blocked_state
# The client is expected to be blocked on a set of keys, we unblock it based on the key
# arg, which itself comes from @db.ready_keys, which is populated when a key that is
# blocked on receives a push
# So we pop (left or right for list, min or max for a set) at key, and send the response
# to the client
if client.blocked_state
response =
pop_operation(key, list_or_set, blocked_state.operation, blocked_state.target)
serialized_response = response.serialize
@logger.debug "Writing '#{ serialized_response.inspect } to #{ client }"
unless Utils.safe_write(client.socket, serialized_response)
# If we failed to write the value back, we put the element back in the list or set
rollback_operation(key, response, blocked_state.operation, blocked_state.target)
@server.disconnect_client(client)
return
end
else
@logger.warn "Client was not blocked, weird!: #{ client }"
return
end
true
end
def serve_clients_blocked_on_lists(key, list_or_set, clients)
generic_serve_clients(clients, list_or_set) do |client, clients_waiting_on_different_type|
if is_client_blocked_on_list?(client)
handle_client(client, key, list_or_set)
else
clients_waiting_on_different_type << client
nil
end
end
end
def serve_clients_blocked_on_sorted_sets(key, list_or_set, clients)
generic_serve_clients(clients, list_or_set) do |client, clients_waiting_on_different_type|
if is_client_blocked_on_sorted_set?(client)
handle_client(client, key, list_or_set)
else
clients_waiting_on_different_type << client
nil
end
end
end
def generic_serve_clients(clients, list_or_set)
unblocked_clients = []
clients_waiting_on_different_type = []
cursor = clients.left_pop
while cursor
client = cursor.value
unblocked_clients << client if yield(client, clients_waiting_on_different_type)
if list_or_set.empty?
break
else
cursor = clients.left_pop
end
end
return unblocked_clients, clients_waiting_on_different_type
end
def serve_client_blocked_on(key, list_or_set, clients)
unblocked_clients = []
clients_waiting_on_different_type = List.new
case list_or_set
when List then
unblocked_clients, clients_waiting_on_different_type =
serve_clients_blocked_on_lists(key, list_or_set, clients)
when RedisSortedSet
unblocked_clients, clients_waiting_on_different_type =
serve_clients_blocked_on_sorted_sets(key, list_or_set, clients)
else
@logger.warn "Found neither a list or sorted set: #{ key } / #{ list_or_set }"
raise "Found nil or neither a list or sorted set: #{ key } / #{ list_or_set }"
end
# Take all the clients we set aside and add them back
clients_waiting_on_different_type.each do |client|
clients.right_push(client)
end
unblocked_clients
end
def is_client_blocked_on_list?(client)
return false unless client.blocked_state
[ :lpop, :rpop, :rpoplpush ].include?(client.blocked_state.operation)
end
def is_client_blocked_on_sorted_set?(client)
return false unless client.blocked_state
[ :zpopmax, :zpopmin ].include?(client.blocked_state.operation)
end
end
end
listing 10.71 The updates to the BlockedClientHandler class for sorted sets
handle is called with the key of a collection, either a sorted set or a list, that was just added. The same way we used to, we get the list of all clients blocked for that key, through the @db.blocking_keys dictionary and we also get the actual collection, from @db.data_store, which is still of an unknown type at this point. It could either be a List or a SortedSet. We call serve_client_blocked_on with all the variable we just created.
In serve_client_blocked_on we check for the type list_or_set and call the appropriate method depending on what we find, serve_clients_blocked_on_lists or serve_clients_blocked_on_sorted_sets. Each of these methods make use of the generic generic_serve_clients method, in which we left pop from the clients list, to get the client who is first in line.
The clients list acts a queue where elements are right pushed and left popped to use a FIFO mechanism. We also create a new list, clients_waiting_on_different_type which will become handy shortly.
Because we might be able to unblock more than one client, we iterate over all the nodes in client, and for each of them we yield back to either serve_clients_blocked_on_sorted_sets or serve_clients_blocked_on_lists. We need to check which type of keys the client was blocked for. If they ended up in the blocked queue because of BLPOP, BRPOP or BRPOPLPUSH, they need any of the keys they’re blocked on to become a new list, and if they were blocked because of a BZPOPMIN or BZPOPMAX command, they need it to be a sorted. An example will illustrate this clearly:
127.0.0.1:6379> BLPOP something something-else 0
While this client is blocked, if I open another redis-cli and run the following:
127.0.0.1:6379> SET something 123
OK
127.0.0.1:6379> ZADD something-else 0 a 0 b
(integer) 2
Then the first client is still blocked, because neither something or something-else were created as a List. The same goes if a client is blocked on a sorted set, it will only unblock if one the keys is created as a sorted set.
We check for this with the methods is_client_blocked_on_list? and is_client_blocked_on_sorted_set? which both look at the operation attribute of the BlockedState object to determine which type of object the client is waiting for. If they match, that is if the client is waiting for a List and list_or_set is a List, or the other way around for sorted sets, then we proceed and call handle_client, otherwise we accumulate the clients in a different array, to make sure they are not deleted from the queue and so they are eventually unblocked in the future.
handle_client returns a boolean, because it might actually fail to unblock the client in some uncommon edge cases. generic_serve_clients accumulates the unblocked clients in the unblocked_clients array, and it returns it, alongside all the clients that were waiting for the the other type.
These two arrays are handled in serve_client_blocked_on, where we iterate through clients_waiting_on_different_type to put them back in the queue, and unblocked_clients is returned to handle.
handle_client has been updated as well, mainly to rename the variable list to list_or_set, but the actual changes are in the pop_operation and rollback_operation methods. These methods use a case/when against the operation attribute to determine what to do. We need to add branches for :zpopmax and :zpopmin in order to be able to perform the right pop operation when a sorted set is created and we’re in the process of unblocking a client.
For :zpopmax we call RESPArray.new([ key ] + @db.pop_max_from(key, list_or_set)) and for :zpopmin we call RESPArray.new([ key ] + @db.pop_min_from(key, list_or_set)). The array returned in each case is a three-element array with the name of the sorted array, the key, and the member/score pair. The key is required because a client might pass more than a single key to block on and without returning it, they wouldn’t know which of the keys triggered the unblocking.
We need to add these two methods to the DB class:
module BYORedis
class DB
# ...
def pop_max_from(key, sorted_set)
generic_pop(key, sorted_set) do
sorted_set.pop_max(1)
end
end
def pop_min_from(key, sorted_set)
generic_pop(key, sorted_set) do
sorted_set.pop_min(1)
end
end
# ...
end
end
listing 10.72 The pop_min_from and pop_max_from methods in the DB class
Both methods wrap the specific pop method from RedisSet and use generic_pop to make sure that if the popped element was the last one the sorted set is deleted from the database
In the rollback_operation we can handle both operations the same way since calling RedisSortedSet#add will insert the element at the correct location.
This wraps up the blocking commands. We now have three more small commands to add to complete this chapter.
Misc commands
There are three more commands left to add to complete all the sorted set commands. Let’s start with ZCOUNT which counts the number of elements in the given score range. Its format is the following according to the Redis Documentation:
ZCOUNT key min max
We kept the simplest commands for last, this one takes three arguments, the key of the sorted set and the min and max values using the same semantic as we’ve seen in ZRANGEBYSCORE, that is we can use the exclusive prefix (.
module BYORedis
module SortedSetUtils
# ...
def self.generic_count(db, args)
Utils.assert_args_length(3, args)
key = args[0]
min = args[1]
max = args[2]
sorted_set = db.lookup_sorted_set(key)
count = yield(sorted_set, min, max) || 0
RESPInteger.new(count)
end
end
# ...
class ZCountCommand < BaseCommand
def call
SortedSetUtils.generic_count(@db, @args) do |sorted_set, min, max|
range_spec = Utils.validate_score_range_spec(min, max)
sorted_set&.count_in_score_range(range_spec)
end
end
def self.describe
Describe.new('zcount', 4, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.73 The ZCountCommand class
We use the generic_count method from ZCountCommand, because we’ll be able to use later with ZLEXCOUNT. The generic method validates the argument array length, looks up the sorted set and yields the value back to the call method, and return what the block returns, as an Integer, which is the count value.
The min and max value are sent back to the caller with yield because their handling will depend on the type of range we’re expecting. With this command we need to treat them as range score items and in ZLEXCOUNT we will treat them as lex range items.
We use validate_score_range_spec to create a new instance of GenericRangeSpec, specific to scores, and pass it to count_in_score_range_spec on RedisSortedSet:
module BYORedis
class RedisSortedSet
# ...
def count_in_score_range(range_spec)
return 0 if range_spec.empty? ||
no_overlap_with_range?(range_spec) { |pair, _| pair.score }
case @underlying
when List then count_in_score_range_list(range_spec)
when ZSet then @underlying.count_in_score_range(range_spec)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
def generic_count_list(range_spec)
count = 0
entered_range = false
@underlying.each do |pair|
in_range = range_spec.in_range?(yield(pair))
if in_range
entered_range ||= true
count += 1
elsif entered_range
break
end
end
count
end
def count_in_score_range_list(range_spec)
generic_count_list(range_spec, &:score)
end
end
end
listing 10.74 The RedisSortedSet#count_in_score_range method
The first two lines try to return early if the range spec is empty or if there’s no overlap with the set, otherwise we call count_in_score_range_list or ZSet#count_in_score_range. Let’s in RedisSortedSet and look at the list method.
Most of the work is performed by the generic_count_list method, which iterates from the left to right with each, and keeps track of when it enters the range with the entered_range boolean. Determining if an element is in range is done by calling in_range? with the range spec, with the value returned by yield(pair), which in this case returns the score attribute of pair.
We keep incrementing the count variable as long as we find elements in the range, and as soon as we find an element outside of the range, we exit early, since there’s no point in continuing iterating at this point.
The ZSet case can be optimized thanks to the SortedArray class:
module BYORedis
class ZSet
# ...
def count_in_score_range(range_spec)
generic_count(range_spec, &:score)
end
private
# It is more than recommended to check that there is some overlap between the range_spec and
# this set RedisSortedSet provides that with the no_overlap_with_range? method
def generic_count(range_spec, &block)
first_in_range_index = @array.first_index_in_range(range_spec, &block)
last_in_range_index = @array.last_index_in_range(range_spec, &block)
# We need to add 1 because the last index - the first index is off by one:
# < 1, 2, 3, 4, 5>, with the range 2, 4, has the indices 1 & 3, 3 - 1 + 1 == 3
# If 4 had been specified as exclusive with (4, then the result should be 2, because
# only the scores 2 & 3 (at index 1 & 2) fit in that range, and 2 - 1 + 1 == 2
last_in_range_index - first_in_range_index + 1
end
end
end
listing 10.75 The ZSet#count_in_score_range method
ZSet#count_in_score_range acts very similarly to count_in_rank_range_list, it is a wrapper around the method that actually does the work, generic_count in this case, with a block that returns the score attribute of a Pair instance.
generic_count uses methods we’ve created before on SortedArray, first_index_in_range and last_index_in_range, which will both be “fast” by relying on bsearch_index under the hood. What’s important to note is that it won’t require a full iteration of the array, and each call to bsearch_index will have a O(logn) time complexity, making the time complexity of generic_count O(2logn), which happens to be on the same ballpark than O(logn). Put simply, the number of steps it takes to complete this method will grow as the set grows, but the growth will not be near to a linear growth, essentially, it will slow down “slowly”.
Once we have the first and last index, we can subtract them and add one to get the number of items in the range.
We could have chosen a different approach, to only call first_index_in_range, to “jump” to the first element in the range, and to keep counting from there until we find an element outside the range. This alternative approach might actually be more efficient for very small ranges, within a very large sorted sets. In this case the binary search approach, while always being more efficient than a full scan, will require a lot of iterations to reach the element it’s trying to find, but if the range is really small, it might actually be really fast to advance by that many items in the range and return that small count.
Being able to find an acceptable threshold is complicated, and would require a lot of manual testing to find appropriate values.
There would be a potential problem by always using this alternative approach, we could trigger a very slow count if the range was really big, say, more than a million items, we’d be looping a million times. The approach we picked might not always be the best but it will never be terrible thanks to the O(logn) time complexity of the binary search, which is at least a good starting point.
An approximation of the number of steps required to find an element with bsearch_index can be done by using the log2n function, the binary logarithm. log2n(1,000,000) ~= 19. This is because at first the binary search operates on the full array, 1,000,000 items, it then slices it in half and looks at 500,000, and so on, and after doing that 19 times, there should only be one or two items left. This tells us that in the worst case scenario, calling first_index_in_range and then last_index_in_range would require about ~38 iterations to retrieve both items, which is way less than iterating a million times to count items one by one!
The ZLEXCOUNT command is very similar, except that it works with a lexicographic range instead of a score range, its format is the following according to the Redis Documentation:
ZLEXCOUNT key min max
Let’s create the ZLexCountCommand class:
module BYORedis
# ...
class ZLexCountCommand < BaseCommand
def call
SortedSetUtils.generic_count(@db, @args) do |sorted_set, min, max|
range_spec = Utils.validate_lex_range_spec(min, max)
sorted_set&.count_in_lex_range(range_spec)
end
end
def self.describe
Describe.new('zlexcount', 4, [ 'readonly', 'fast' ], 1, 1, 1,
[ '@read', '@sortedset', '@fast' ])
end
end
end
listing 10.76 The ZLexCountCommand class
We call generic_count the same way we did with ZCOUNT, but this time we use validate_lex_range_spec with the min and max variable, to create an instance of GenericRangeSpec specific to lexicographic order. We then call count_in_lex_range from RedisSortedSet:
module BYORedis
class RedisSortedSet
# ...
def count_in_lex_range(range_spec)
return 0 if range_spec.empty? ||
no_overlap_with_range?(range_spec) { |pair, _| pair.member }
case @underlying
when List then count_in_lex_range_list(range_spec)
when ZSet then @underlying.count_in_lex_range(range_spec)
else raise "Unknown type for #{ @underlying }"
end
end
# ...
private
# ...
def count_in_lex_range_list(range_spec)
generic_count_list(range_spec, &:member)
end
end
end
listing 10.77 The RedisSortedSet#count_in_lex_range method
count_in_lex_range is very similar to count_in_rank_range, with the same early return check, and also delegates to two methods, count_in_lex_range_list and ZSet#count_in_lex_range. Both have these methods make use of the generic methods we created earlier and are very concise. count_in_lex_range_list can use generic_count_list, which does the iteration and counting work and only need a block to tell it what attribute to use from Pair instances.
The same goes for ZSet#count_in_lex_range, which uses generic_count giving it the range spec to use, and telling it to use the pair attribute from the Pair instances:
module BYORedis
class ZSet
# ...
def count_in_lex_range(range_spec)
generic_count(range_spec, &:member)
end
# ...
end
end
listing 10.78 The ZSet#count_in_range method
This wraps up the ZLEXCOUNT method.
Finally, the ZINCRBY command increments the score of a member by the given increment value, its format is the following according to the Redis Documentation:
ZINCRBY key increment member
The command is very similar to HINCRBYFLOAT, and performs a floating point increment, with all the infinity and NaN handling it requires.
Let’s create the ZIncrByCommand class:
module BYORedis
# ...
class ZIncrByCommand < BaseCommand
def call
Utils.assert_args_length(3, @args)
incr = Utils.validate_float(@args[1], 'ERR value is not a valid float')
key = @args[0]
member = @args[2]
sorted_set = @db.lookup_sorted_set_for_write(key)
new_score = sorted_set.increment_score_by(member, incr)
RESPBulkString.new(Utils.float_to_string(new_score))
rescue InvalidFloatString
RESPError.new('ERR hash value is not a float')
rescue FloatNaN
RESPError.new('ERR resulting score is not a number (NaN)')
end
def self.describe
Describe.new('zincrby', 4, [ 'write', 'denyoom', 'fast' ], 1, 1, 1,
[ '@write', '@sortedset', '@fast' ])
end
end
end
listing 10.79 The ZIncrByCommand class
Once the sorted set is loaded, we call RedisSortedSet#increment_score_by:
module BYORedis
class RedisSortedSet
# ...
def increment_score_by(member, increment)
current_score = score(member) || BigDecimal(0)
new_score = Utils.add_or_raise_if_nan(current_score, increment)
add(new_score, member)
new_score
end
# ...
end
end
listing 10.80 The RedisSortedSet#increment_score_by method
If the result of score(member) is nil, which would happen if member is not already in the set, then we default it to 0. Once loaded, we safely add the increment value to it. Redis does not store NaN values so we use the method from Utils to raise a FloatNaN error if this happens. The new score is then either added or updated with the add method, depending on whether or not member was already in the set, but add knows how to take care of that.
The FloatNaN exception is handled in the command class and returns the appropriate error message in that case, otherwise the result is returned as a string, because RESP2 does not have support for floating numbers.
Conclusion
You can find the code on GitHub
We have now implemented all the native data types, with the exception of Streams. In the next chapter we will add support for the bitmap related commands, which operate on string values but almost behave as a different data type.
Liked what you read? Consider subscribing to stay updated!
And if you feel extra generous, consider donating!